emoji、sticker、meme的英文语意和技术原理
在一些聊天 im 软件中,我们对表情已经非常熟悉了。今天我们来学习下英文中常用来表达表情的 emoticon、smiley、emoji、sticker、meme。
表情符号:emoticon 和 smiley
emoticon:/ɪˈmoʊ.t̬ə.kɑːn/。
smiley:/ˈsmaɪ.li/
emoticon 这个单词是由 emotion 情绪演变而来,意为表示情绪的 icon 图标,而 smiley 也显而易见是由 smile 微笑演变而来。
所以,这俩单词通常就是表示所谓的“表情符号”。
那么,啥叫表情符号呢,大家可以仔细回想一下当年用 QQ 的时候,是怎么来表达我们心情的表情的,是不是用标点符号拼起来?我们直接搬运一些表情符号来看看:

结论:emoticon 和 smiley 就是指的早期用标点符号组成的表情。现在不太常用了。
卡通表情图像:emoji
emoji:/iˈmoʊ.dʒi/
注意读音是“亿谋知 A”。
所谓 emoji 严格来说,是指的大家在各个聊天软件中点击“表情功能”后第一个出现的表情菜单里那一堆简洁的表情图像,举例这个笑哭 😂 的表情就是了。
要知道,这种 emoji 表情并不是聊天软件专属的概念。他就是一个独立的“卡通图像表情”的概念,而且他并不是中国独有的概念,他在全世界都有,甚至 2010 年已经把这些符号编进了 Unicode 字符编码。不过呢,Unicode 编码表只是规定了 Emoji 的码点和含义,并没有规定它的样式。
举例来说,码点 U+1F600 表示一张微笑的脸,但是这张脸长什么样,则由各个系统自己实现。如果用户的系统没有实现这个 Emoji 符号,用户就会看到一个没有内容的方框,因为系统无法渲染这个码点。例如这个笑哭的表情,我的 mac 电脑上显示成:

而其他人的安卓手机可能会显示成:

因此,无论从技术上还是从生活感知上,你都可以认为 emoji 就是一种“被业界标准承认了的文字”而已,他本质上就像我们的 ABCDEFG 的每个字母一样,一个表情本质上就是一个特殊的字符。
以微笑来举例,像上文所讲的“emoticon”他是人为的用多个“字符”刻意拼凑组合,让最终效果看起来像是一个“微笑”。而 emoij 则是从官方字符层面就给你创造了专门的字符来表达“微笑”。
每个 emoji 表情就像汉字一样,在 unicode 表中都有自己的一个位置。以下是 wikipedia 关于 emoji 的 unicode 编码区位置部分截图:

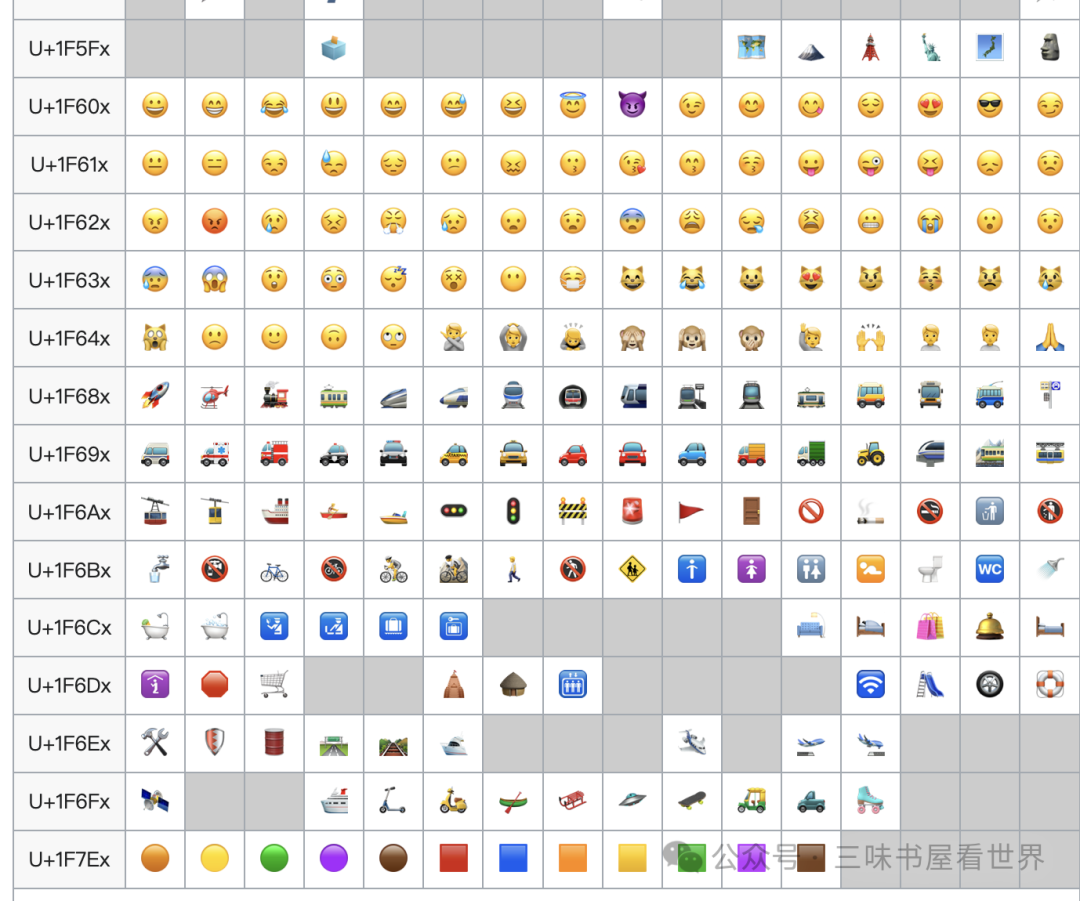
目前,无论是各种主流输入法还是主流聊天 IM 软件,在输入表情方面,必然会优先支持 emoji 表情的选择。因为 emoiji 这在全世界都是最常用的。
例如我们常见的一些 im 聊天软件的表情功能示例:
QQ(mac os 版本):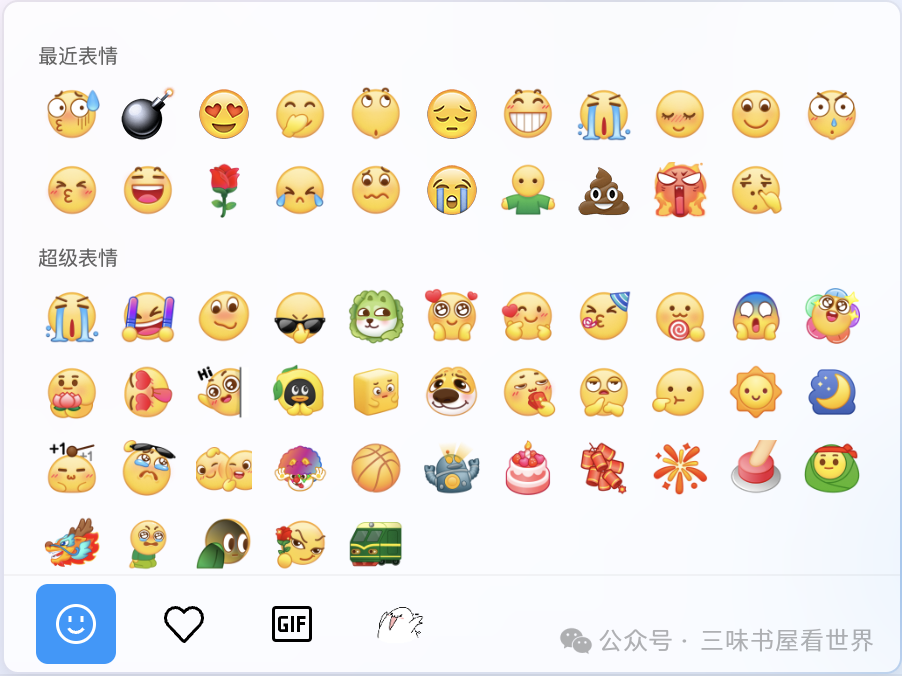
xx(mac os 版本)
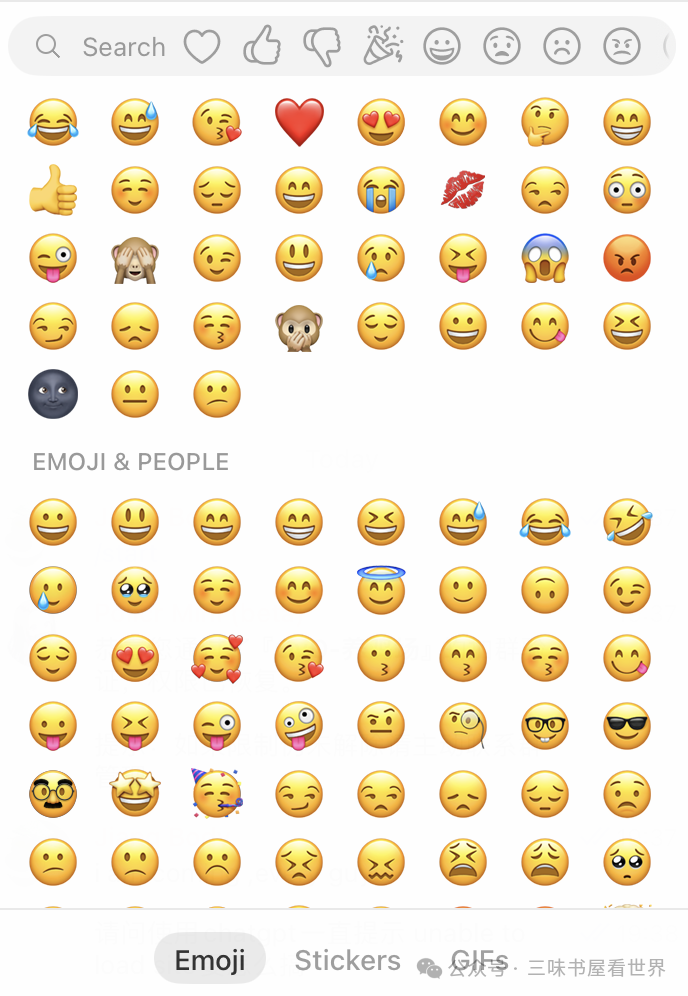
微信(mac 版本)
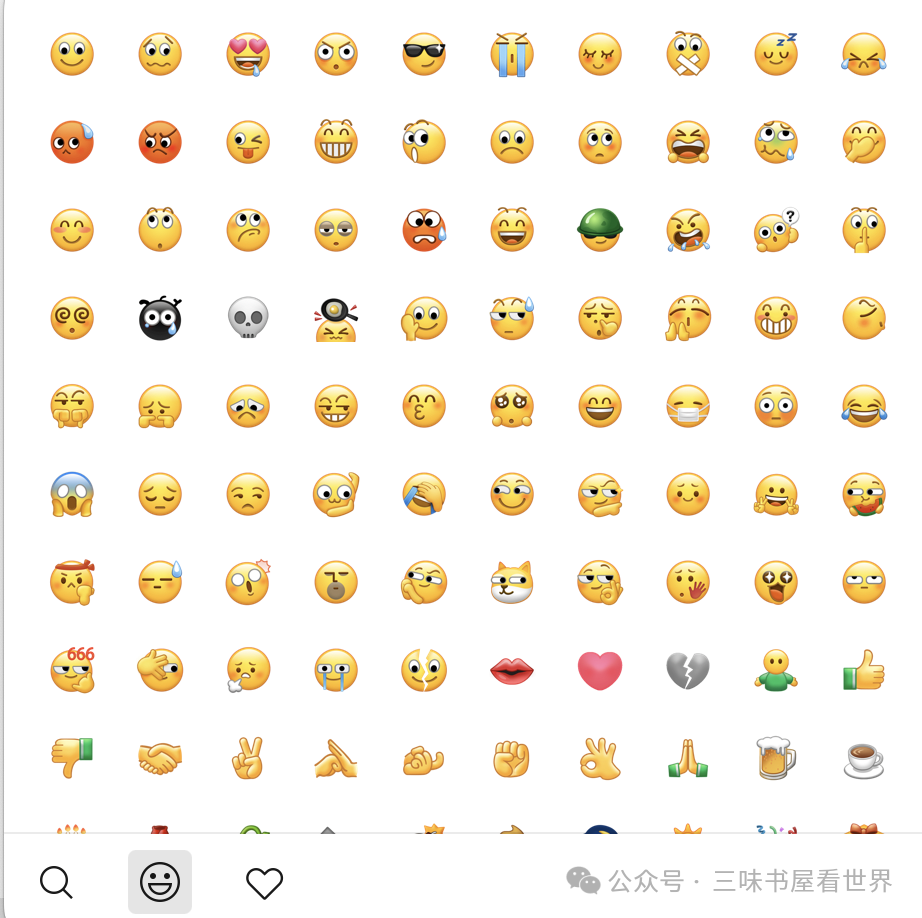
甚至包括非 IM 软件,例如系统自带的输入法,也可以调出本系统输入法所提供的表情符号。如下是 mac 电脑默认输入法可以调出的表情插入界面:
sticker 表情贴纸
所谓 sticker 是指的表情贴纸。如果肤浅一点理解,可以理解成 IM 聊天软件给我们提供的各种“内置精选贴纸表情包”。
这类表情包一般是由专业设计师制作上传,并且一个表情包内是通过某一个特定的“品种”(例如老虎、兔子之类)来表达各种情绪。而从技术层面理解,这种表情本质上是一个图,而并非 unicode 字符。只是对于 im 内置表情包来说,你可能无法知道他的真正图片格式。
例如某软件(微信)内部的添加精品表情包的功能:
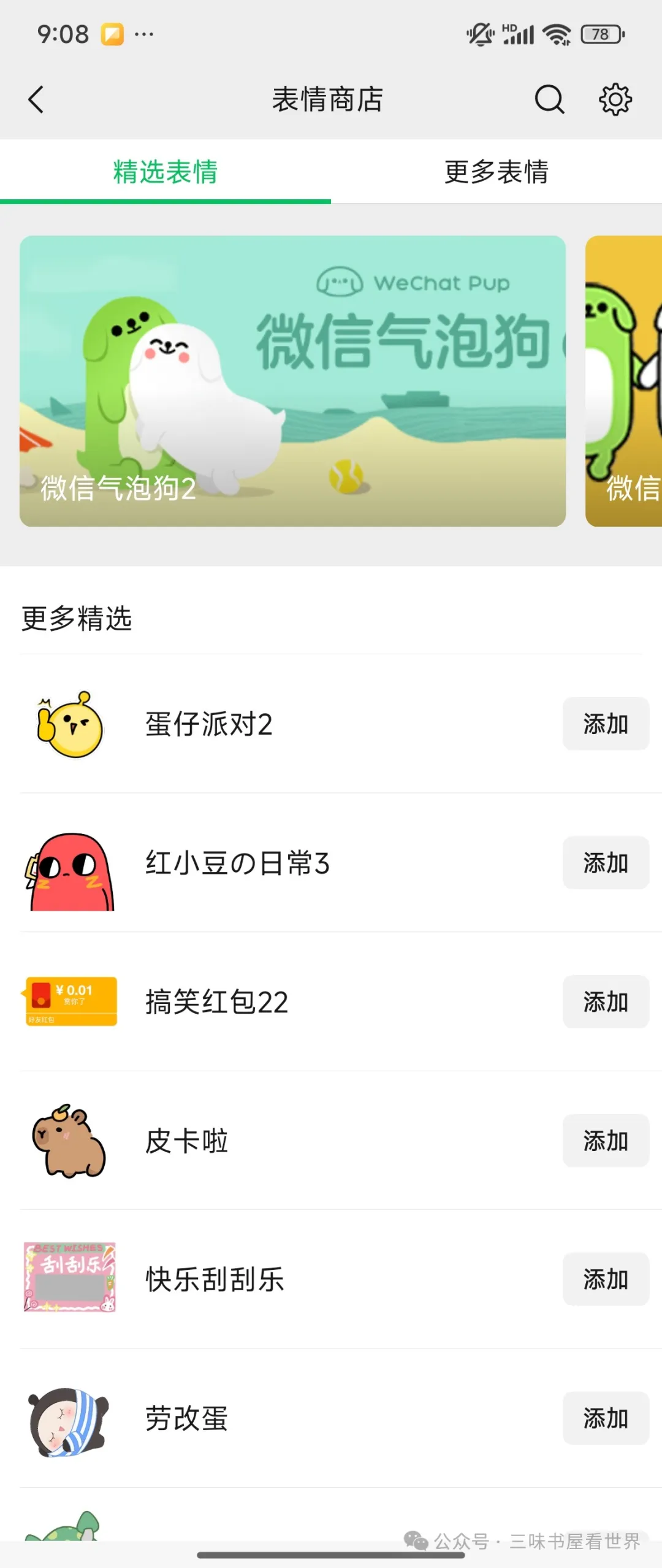
添加后可以在聊天界面使用:
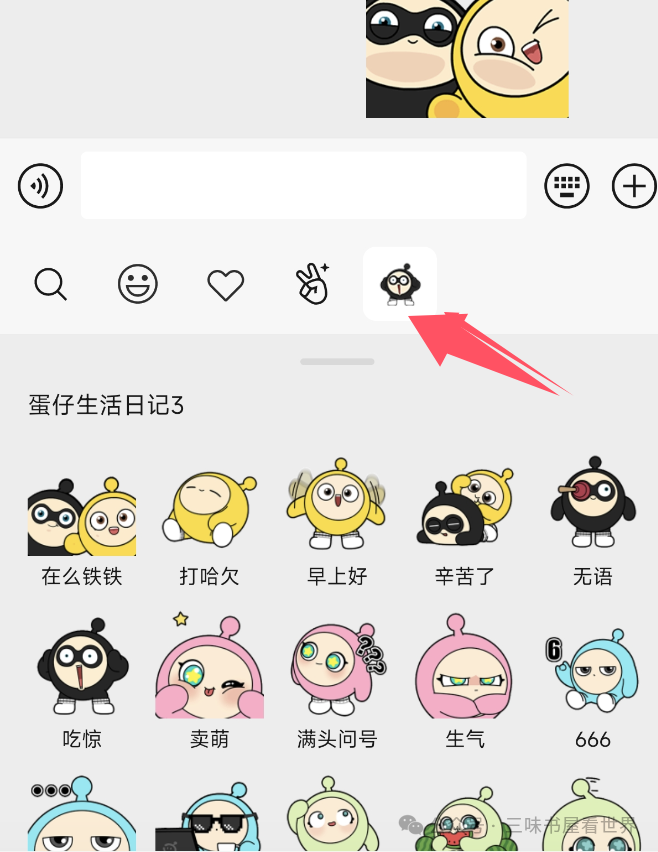
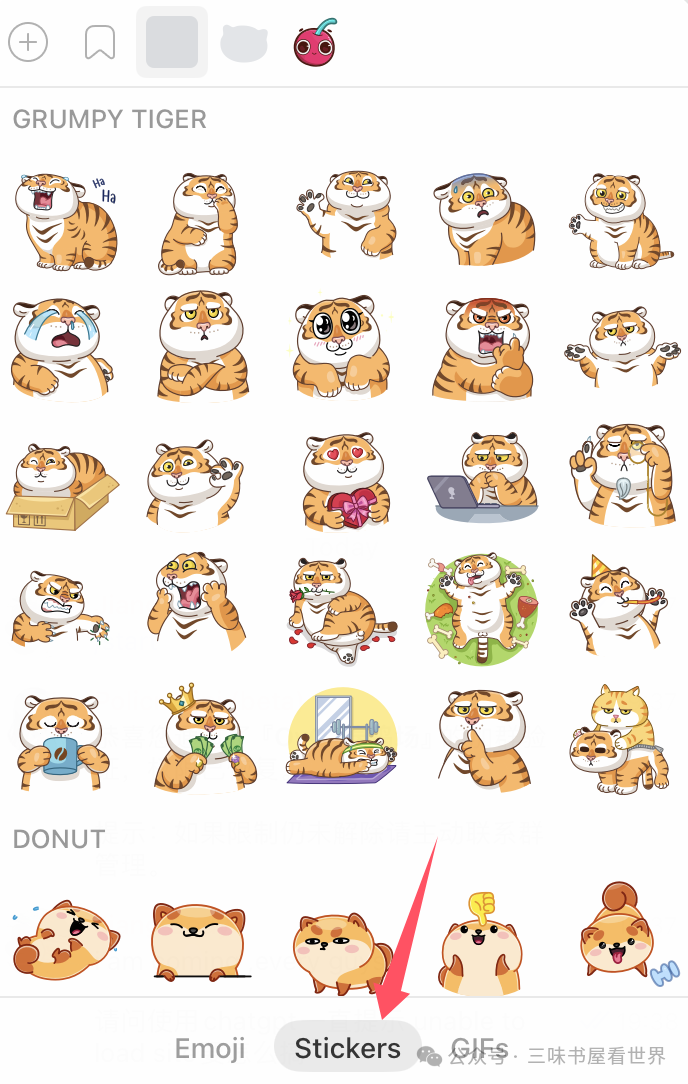
一些国外软件,则会直接显示成 stickers 菜单:
自定义表情图片 meme
meme:/miːm/
所谓 meme 是指的自行制作的图片表情。来一张图你就立刻理解了:

但实践中我没怎么听说过 meme 这个单词,估计 meme 这种图片表情其实在 IM 聊天软件中也是可以添加到表情工具菜单内,因此它看起来仿佛跟 sticker 贴纸也差不多的使用方法。因此实际生活中,可能也可以叫做 sticker 贴纸。
这种在近些年的聊天软件和贴吧以及各类其他文字自媒体平台(包括公众号文章)都使用甚广。因为他能结合当前热点事件,通过热点事件图片+热点文案,由用户自己自定义制作成一张图片,然后将其作为表情发布到文章或聊天里面,其起到更好的表达情绪引起共鸣和幽默的效果。
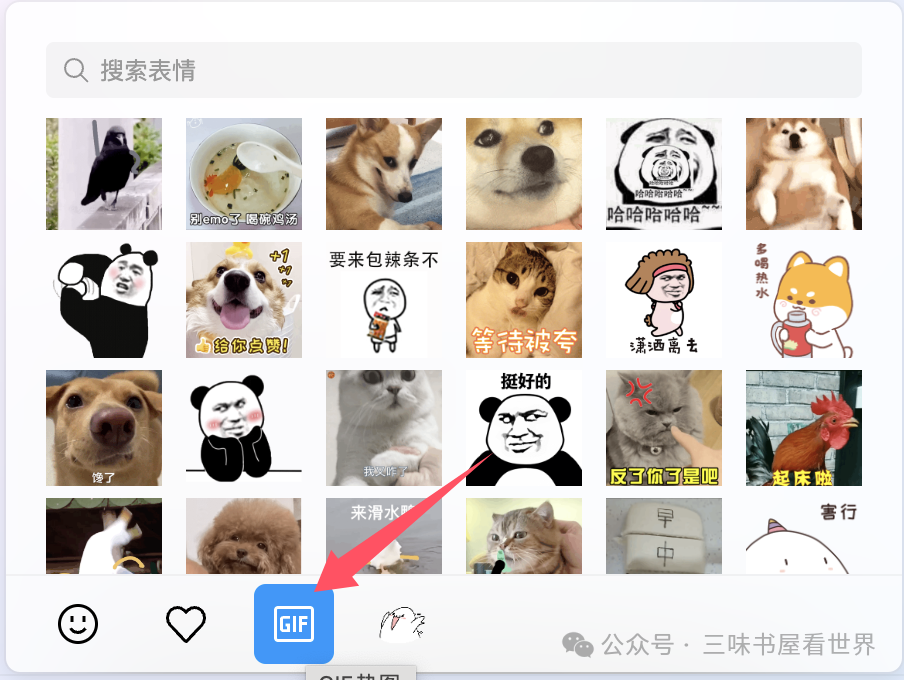
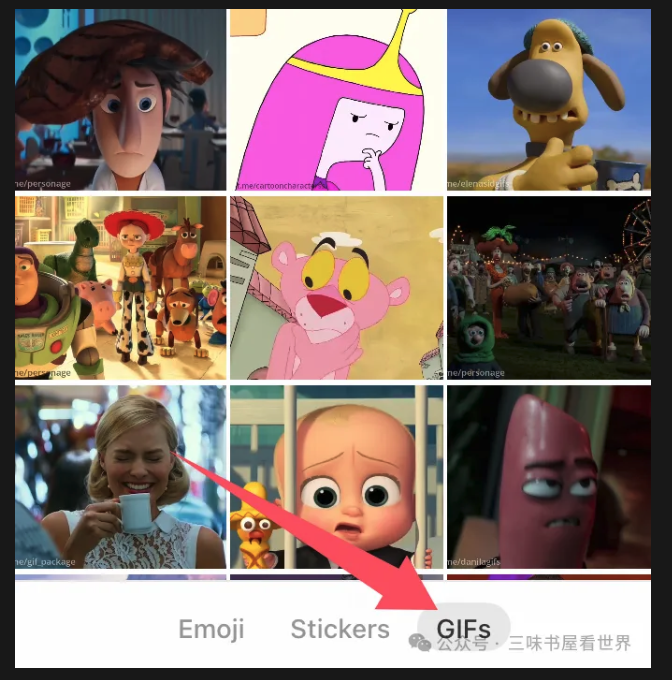
在聊天软件中,这类功能一般会显示成 GIF,且 GIF 菜单下允许用户上传图片变成自己的专属表情图片以供后续聊天时使用。例如国内的 QQ 等软件:
关于 unicode 和 emoji 的转换
既然 emoji 就是个文字,那么就存在“unicode 编码和字符互相转换”的问题。本节在技术层面,了解下 emoji 表情和 unicode 码点之间互相转换的方法。
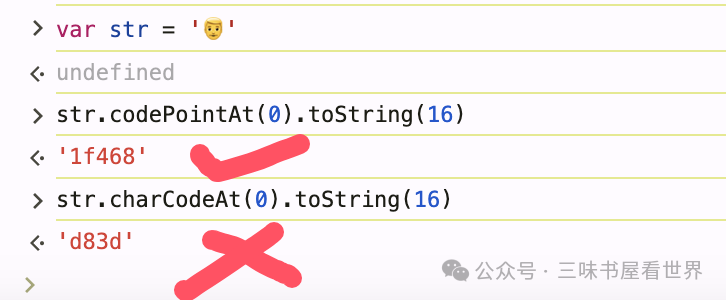
👨 这个表情的 unicode 字符编码是十六进制表示法的“0x1F468”。那么在 JavaScript 中,则可以直接将该编码传给 String.fromCodePoint 函数来生成结果字符串(由于 1F468 已经超过 2 个字节,因此必须使用 ES6 的 fromCodePoint)。
1 | String.fromCodePoint("0x1F468"); |
执行结果:
反过来,读取 unicode 字符串变量中的单个字符并返回十六进制,则用 charPointAt:
emoji 表情的多表情拼接
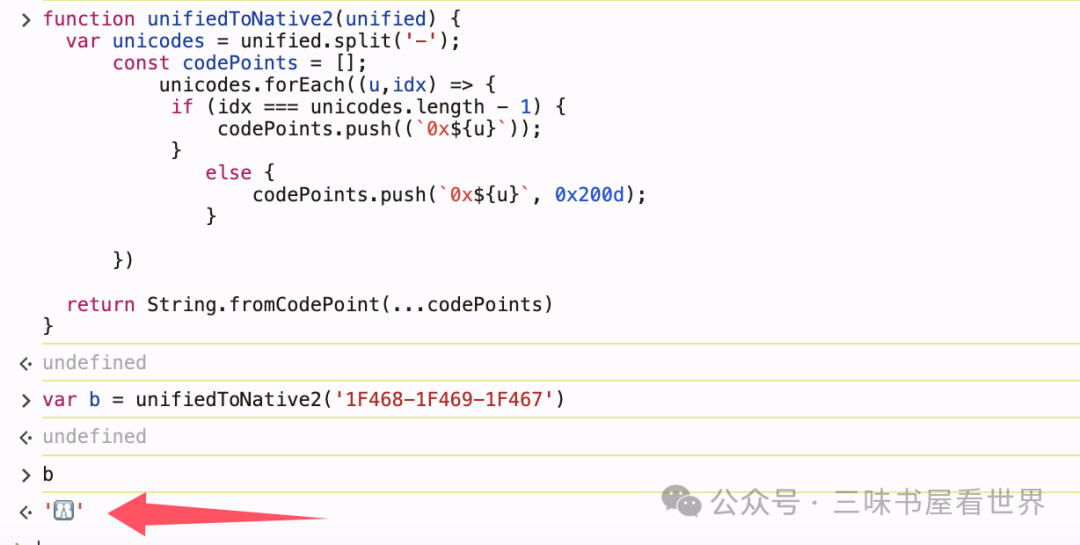
就像十几年前,我们会用多个标点符号来人为拼凑成一个新的含义的符号。而在 emoji 时代,很多软件甚至提供了基于 emoji 表情的拼接合并能力。例如我们如果用拼接字符“0x200d”把如下 3 个 emoji(男人+女人+孩子)拼接起来,他竟然可以变成一个“家庭”。
男人:0x1F468
女人:0x1F469
女孩:0x1F467
拼接方法:
1 | function unifiedToNative2(unified) { |
拼接实验结果,👨👩👧:
像聊天软件的表情列表中的这些表情,他们应该是由多个 unicode 字符拼接而成,你看到的表情列表仅仅是让你看到是单个表情而已。当你把他拷贝到 js 代码中解析,会发现他由 5 个字符组成(其中包含 2 个零宽字符):

以下是我从 im 软件中把该“家庭”表情拷贝出来并打印的 unicode16 进制编码值结果,跟我们上文实验输入的编码值完全相同:

js 中准确获取字符串的 length 长度
虽然 es6 提供了 fromCodePoint、codePointAt、以及 forof 对 unicode 四字节字符的支持。然而其 length 属性为了向后兼容就依然只能识别小于等于 2 字节字符,因此当我们使用“𫟷”这个 3 字节汉字来打印长度的时候,你会发现 js 会把他识别成两个字符。此时我们可以用 Array.from 来解决超过 2 字节字符的长度计算准确性问题。如下图:

本文参考文献
https://www.xdf.cn/bbc/yingyu/202012/11136223.html
https://www.douban.com/note/227408401/?_i=11557657ysRQAh
https://juejin.cn/post/6844903637555101704
https://www.zhangxinxu.com/study/201611/chinese-language-unicode-range.html