REGEXPER正则表达式图形工具的使用
我们在使用正则表达式的时候,看到一坨繁琐的式子经常头大,如果转换成图形描述或许更加清晰点。本文介绍一个叫做 REGEXPER 的网站,REGEXPER 网站提供了一种工具,可以把你的正则表达式转换为 铁路图(Railroad Diagram),通过铁路图,或许能让我们更清晰的理解我们所编写的正则表达式。
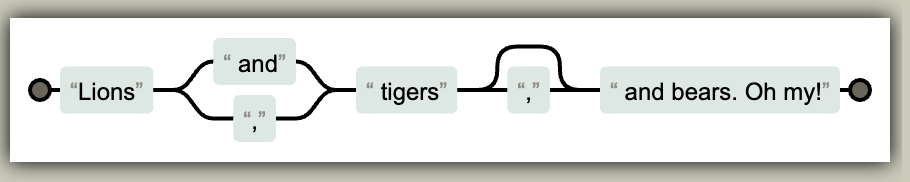
看上面这张图,这就是一张铁路图。这种图可以提供一种更直观的方式让我们在面对正则里面各种复杂的嵌套循环、可选的元素时化繁为简。这种图最简单的看法就是沿着线条从左往后看。如果你碰到一个分支 branch, 这里表示有多种选择,你可以任选一条路径之一往下看(有的路径还会在某一时刻再折回前面来,比如循环的时候)。为了能完整的匹配整个图中的表达式,你必须完整的从左到右依次走完整幅图直到末尾。
比如上面这幅图,他的正则表达式是 Lions(?: and|,) tigers,? and bears\. Oh my!。这个表达式将匹配 “Lions and tigers and bears. Oh my!” 或者 “Lions, tigers, and bears. Oh my!”, 即要么使用 and 而不使用牛津逗号,要么使用牛津逗号而不使用 and。这幅图首先描述了你必须先有一个 “Lions” 字符串,这个是必不可少的;接下来你可以在 “ and” 和 “,” 之间进行选择一个。不管你刚刚做的什么选择,接下来必须有一个 “ tigers” 跟着。而这个 “tigers” 后面可以有一个逗号也可以在路径上绕过这个逗号,因此后面这个逗号是可选的。在最后,必须跟着一个固定的字符串 “ and bears. Oh my!”。
下面我们介绍铁路图中的一些元素的含义。
基础元素
这种图中最容易理解的部分就是那些基本的没有选择路径之类的字符或文本串、转义字符、任意字符了。
普通字符字面量

字面量是匹配一个精确的文本字符串。他们展示在一个 浅蓝色 的块里面,内容会用 引号 包裹起来(让你更容易看清任何前导或尾随的空格)。
例如 /a/ 或 /\d+你好/中的你好, 这种正则中的直接字面量,在 REGEXPER 网站中会用 浅蓝色块 包裹起来表示。
正常字符的转义序列

转义序列,在图上会用一个 绿色 的框来包裹,并包含一个对要匹配的字符的描述。其中一些转义字符他会给你转成 16进制表示法,甚至加上特殊的英文名称以让你看的更加清楚。
除了正常的转义,下面几种也跟转义使用的色块类型一样:
- 字符的进制表示法
这种跟上面的转义序列一样,都是用 绿色 块包裹。只是一般会直接把你的进制直接显示出来(不会加上英文名称)。
- 预定义的正则元字符
由于元字符,其实就像 正则表达式中的转义字符,他在正常字符串中没有具体转义含义,但在正则表达式当中,却可以表达某些字符。因此他也算作前文 转义序列 的一种。故用 绿色块 包裹起来。并且 REGEXPER网站 会给该元字符加上英文名称的说明,如 \d 会写作 digit数字.
可见, 正常字符转义、 字符的进制表示、正则中的元字符表示法,他们由于都是一种 字符 的表达形式,因此在 REEXPER 网站中都是用绿色块来包裹表示。
任意字符
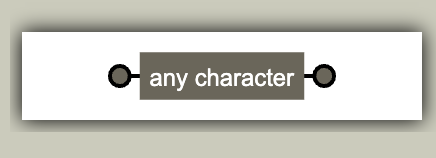
正则图例: /./ 即 任意字符就是正则表达式中的点号。
正则中用 . 号来表示任意字符,而 . 在 REGEXPER 网站中会用黑色块包裹,且显示为 Any Character。他匹配任意的字符。
行首和行尾
^ 和 $ 这俩字符代表行首行尾,比较特殊,也会用 黑色块包裹。
字符集合
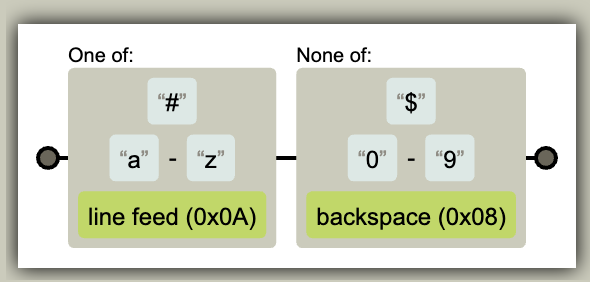
图例: [#a-z\n][^$0-9\b]
字符集是指的多个字符的集合,字符集合会匹配或不匹配一堆的字符。字符集合在图中表现为 包裹着 literal字面量字符 和 转义字符的块。在块的顶部会用 label 标签写明 “包含” 还是 “不包含”。
正则中一般是指的 [a-z] 或 [^a-z] 这种写法。比如 [a-z] 它表达了从小写 a 到小写 z 这 26 个字母的集合。在 REGEXPER 网站中,字符集会用一个灰色块把多个 浅蓝色块和绿色块 包裹起来。寓意: 多个单字符记号的集合。
在灰色块的顶部,会有个英文提示,告诉你这个灰色块是 “One Of” 还是 “None of”。像 [a-z] 这种是OneOf,则表示集合中包含 a 到 z;而像 [^a-z] 则是NoneOf,即表示集合中不包含 a 到 z。
子表达式
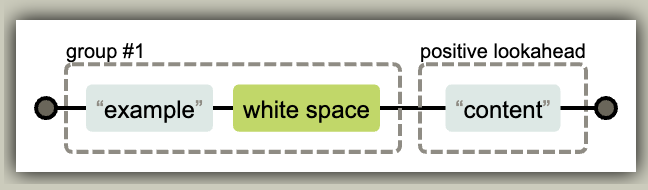
图例: (example\s)(?=content)
子表达式由表达式周围的虚线轮廓来表示。子捕获组会用他的组序号作为 label 标记在框的顶部。零宽断言和负向零宽断言 这种捕获组也都是这样标记(译者注: 因为 ?: ?= ?<= 这些都要在捕获组中来使用,所以也会有个虚线框出现)。
交替/轮换

图例: one\s|two\W|three\t|four\n
交替是提供了一种选择,他在图中用多条路径来表达正则表达式中的多种选择。
量词
量词表达了一个表达式是应该重复还是可选的。他们看起来有点像交替,通过图的分支路径、以及可能会转回来的路径来表达你的选择方式。
这里有一个约定:除非路径上明确用箭头指示了,否则你首选的路径应该是先继续直行,而不是绕行。
0 个或多个

图例: (?:greedy)* 和 (?:non-greedy)*?
这个 零或多 量词指的是重复任意次数的 greedy 这个模式, 由于默认没箭头的情况下走直行,因此左图我们可以看到:先优先执行的话会导致 greedy 循环多次,因此我们执行这个正则表达式的时候,会尽可能多的匹配 n 次 greedy 字符串。
大家注意图的右边这个 non-greedy quantifier 哈。我们看到他图上给上半部分的这条路径提前画了一个 箭头,而下半部分这条路径箭头没有了(被堵死了)。这相当于让你优先走上面的路径,而下面本来是循环多次的路无法走通,故意味着匹配结果是 重复non-greedy零次。 我们看正则表达式本身 (non-greedy)*? ,他其实是在 (non-greedy)* 的基础上,增加了一个所谓的 懒惰模式,即告诉前面这个 * 采用懒惰模式尽可能的少重复。
因此,假如这个正则用来匹配 “non-greedynon-greedynon-greedy”,那么他返回结果是空字符串。
必选(1 个或多个)

图例: (?:greedy)+ 和 (?:greedy)+?
必选量词是说必须匹配一个或多个。注意:它不像上面 0个或多个 似的在图上允许直接跳过。 因此我们从图上看,能往右走的就只剩下中间一条路了。下面这条路其实你看它不是从左边起点画起出发的,而是从右边往回走的一条路,但由于没有了箭头,所以你也不能往回走了。
因此最终结果是,右边这幅图只能匹配 non-greedy 一次。其实从正则表达式本身来看,就是对 + 这个量词采用懒惰模式进行匹配。
optional 可选

图例: (?:greedy)? 和 (?:non-greedy)??
可选是指的匹配这个模式最多一次。可以注意到他没有可以回到自身的路径。
range 区间

图例: (?:greedy){5,10} 和 (?:non-greedy){5,10}?
区间是指的要把模式重复一定的数量的次数。这两个例子都提供了一个 (5, 10) 次的区间,图中的 times label 标签写明了这个分支要循环的次数(如图中的 4-9 次)。这个图中的次数值会比正则表达式中写的次数少一次,这是因为这个模式至少在循环之前在路径中会匹配一次。 所以对于本例,这个模式会在正常路径中先匹配一次,然后进入循环匹配 4-9 次,总共是 5-10 次。
大家看右图,其实是 {5, 10} 的懒惰模式。他尽可能的匹配少的次数,所以图中就没有画箭头,意在告诉你标签中写了 4-9 次,你尽可能少的转回来,只要满足要求(比如转 4 次)就继续往后走吧。
总结
- 浅蓝色块: 字面量
- 绿色块: 转义序列
- 灰色块: 任意字符,行首行尾
- 虚线框: 子捕获组
- 实线: 逻辑匹配的前进路径