从零搭建webpack前端类库脚手架[1]-开端
前言
在现代化的前端开发中,webpack已经成为开发必备的打包工具之一。它提供了非常灵活的配置方案,允许开发者以各种各样的形式进行DIY自己的配置。很多大名鼎鼎的类库如 react、vue 都正在或曾经使用webpack来进行项目工程化构建。
但是webpack强大的灵活性和复杂性也给我们带来了无所适从的感觉,我们无从得知其最佳实践是怎样的。所以,我在本系列文章中,我会在讲解webpack基本功能的基础上,基于 webpack 打造一个常见的前端类库项目样板,并基于该项目模板开发一个前端工具类库,最终以 npm 包的方式发布到 npm 仓库。
这个系列文章中会包含前端工程化和开源项目开发流程的一些知识点。主要涉及到的技术点有 webpack, babel, npm, mocha, chai, eslint, git, git hook, github Travis CI 等工具库或模块的使用,我们可以从中学会一个基于 webpack 的完整前端开源类库项目的开发和发布流程。
最终成果放在了我的Github上面:
- felib-template 一个前端库模板,基于ES6开发,使用了webpack进行模块的打包
- felib-flow-template 一个集成了 flow 静态类型检查的项目脚手架.
- fet 基于felib模板来实现的一个精简的前端工具库,可用于常见的对性能要求比较高的
2c类的前端页面中
也欢迎大家使用我的 fet-cli 前端cli工具进行各类前端或Node项目初始化,希望大家多多提意见督促我进行改进。
webpack 介绍
WebPack可以看做是模块打包机(module bundler)或者叫模块编译系统(module building system):它做的事情是,分析你的 JavaScript 依赖,找到所有资源模块,编译一些浏览器不能直接运行的拓展语言(如 Scss,TypeScript等),并将其打包为浏览器可运行的 JavaScript 代码或附加资源(如 html、css)以供浏览器使用。
webpack把所有的资源(css、js、ts、img)都视为模块,并使用编程的方式对他们进行组织、转译、模块化打包。通过一些插件可以将其中 css 这样的模块进行抽离成单独的文件,以适应浏览器端的css运行环境。
模块化发展历程
刀耕火种
JavaScript中最初解决模块化问题的时候,开发者使用全局对象作用域或匿名函数的方式来隐藏局部变量,防止全局污染。严格意义上来说,这不算模块化。但也在历史上一定时期起到一定的作用。
经典模块化
后来 JavaScript 的模块化方案出现,用来解决浏览器中js运行时的模块化问题。他们大多数是以浏览器 runtime loader (我的理解) 的形式出现,例如 AMD、CMD、commonjs 模块规范,其中具有代表性的是 require.js 和sea.js, 也顺带提一下我所熟悉的百度 efe 的 esl。他们通过在浏览器运行时提前加载一个module loader的运行时环境,从而可以让业务的js代码以模块的形式包装、注册和运行。AMD原理可参考百度EFE errorrik大神出品的 玩转AMD - 设计思路
模块合并
当 AMD 和 CMD 实现了js代码的模块化加载之后(或同时),人们顺其自然地可以实现在开发期间保持模块文件的分离(代码编写时文件粒度的模块化),但是如果文件分离过多会导致前端异步请求 js 资源过多。随着前端工程化工具的发展,大家开始使用 grunt、gulp 之类的工具进行模块合并。例如把开发阶段各个分散的 js 模块文件合并到为一个称之为 bundle.js 的文件里进行浏览器加载。这种方式实际上很容易理解,就是简单地把多个 define 包裹的模块函数定义合并为一份代码文件。
此外,基于一些 gulp 流式执行任务的原理,也可以形成复杂的工作构建流程,例如可以针对 JavaScript 源码进行一些预编译工作从而支持更先进的 ESNext 语法;例如可以把 CoffeeScript 的源码模块先 transfer (转译) 为JavaScript,再执行打包等其他任务。
真正的模块化
webpack 的到来带来了真正的模块化。我之所以这样定义 webpack 是因为我认为 webpack 跟之前的模块化在模块打包的过程中是有本质区别的。webpack是能够真正理解模块的,它在JavaScript的运行之前(编译期)就去解析了你的JavaScript代码,从中分析并发现其通过 commonjs 等方式依赖的其他模块并构建出依赖树。最终在编译期间就知道你的项目需要加载哪些模块文件,从而打包出你真正会用到的模块。
如果你写过C++,那么可以这样比喻: 使用webpack之后,相当于你要像 C++ 编程一样写一个 main.cpp 的代码文件,里面用到什么 lib 库你就引用什么库,在编译器进行最终编译时,它会把你引用的类库编译进来,而且还可以运行时动态加载 dll 动态链接库(这在 webpack 中也有动态异步 chunk 的概念)。
也并不是说在 webpack 出现之前,其他工具做不到上面所说的这些,实际上 webpack 打包结果的运作方式跟以前的 require.js 基本是类似的。而我们这里所提到的 webpack 跨时代的意义在于:webpack 是从编译期进行模块依赖解析的思路去解决模块问题的。这种编译式的编程方式使得模块清晰、依赖严谨。在编译器解决模块问题,不仅让我们的模块源码更加简洁,而且可以比运行时添加更多复杂的功能,这给 JavaScript 代码优化带来了更多的可能。
理解 webpack
webpack 本身也是采用了一种 插件式 的机制来开发。其内核只完成最基本的能力,然后对外暴露 loader 和 plugin 拓展机制来支持更多的资源类型和处理过程的自定义。webpack 在加载模块的时候,实际上是由 loader 或自身对模块全文进行解析的。因此,体会过 webpack 同学应该知道,使用 webpack 编译代码的过程是有些慢的,有时大型的项目甚至高达 1-2 分钟。我们仿佛回到了后端开发的悲惨生活中,但也还好,我们可以通过优化 webpack 来提高编译速度,在开发阶段也可以使用 热加载 技术让我们修改代码立即看到效果。
loader
在 webpack 中,一切皆模块。webpack 在加载模块这一环节,创造了一个 loader 的概念,相当于在webpack加载模块之前先由 loader 来处理对应的模块资源文件。webpack 自身只能识别 commonjs/AMD/esmodule 模块化方式编写的 JavaScript模块代码,他通过 loader 这个扩展机制来支持任意资源的加载。只要给 webpack 配上一个合适的 loader,则 webpack 相当于可以处理任何类型的文件,如css、es6模块的代码等。
通过 loader 技术,webpack 可以在打包开始的时候把其他语言转换为JavaScript. 基于此,我们可以大胆地使用ES6(2015), ES7(2016), ES8(2017), ES9(2018), TypeScript, CoffeeScript, 而无需担心浏览器的支持情况。
当所有资源成为JavaScript模块后,webpack便可以植入更多有用的处理逻辑。例如我们可以在代码中 require 一个css资源,配合对应的 loader,那这个css资源会被 webpack 识别并调用对应的 loader 转换为模块,再加上适当的 loader 或插件,它还可以变为一段输出到页面head中的内联style样式的js逻辑代码(如 style-loader 所做的事情)。再比如,我们可以在 css 中引用图片资源,加以适当的loader,我们可以让依赖的超过设置的 limit 大小的图片转换为一个图片路径,而在未达到设定的图片大小时直接把图片编译为css中的 base64 图片字符。
插件
插件实际上是 webpack 暴露出的在打包资源模块过程各个生命周期的 Hook。不同的开发者在生命周期的不同阶段,对打包过程中各个模块或打包结果进行修改、统计等,就实现了各种功能的插件。
例如通过相关插件对打包过程中模块的处理,可以把 css 模块都抽离出来,生成一个单独css文件。
与gulp,grunt区别
有时你会感觉webpack和gulp之类的工具仿佛很像,看起来他们都在做打包这种事情。上文我也已经讲过了,他们结果看起来是一样的,但过程的本质是不一样的。 默认情况下webpack就是会解析所有依赖到的模块的代码的,而gulp默认并不会读取并解析你JavaScript模块的代码内容(除非你通过plugin插件来实现)。
下面以两幅图来说明。
这是gulp的运行方式: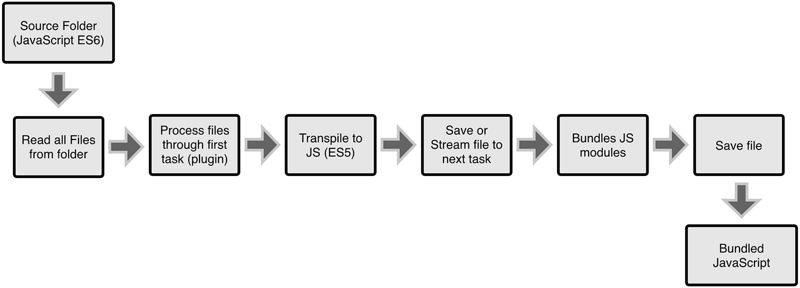
这是webpack的运行方式: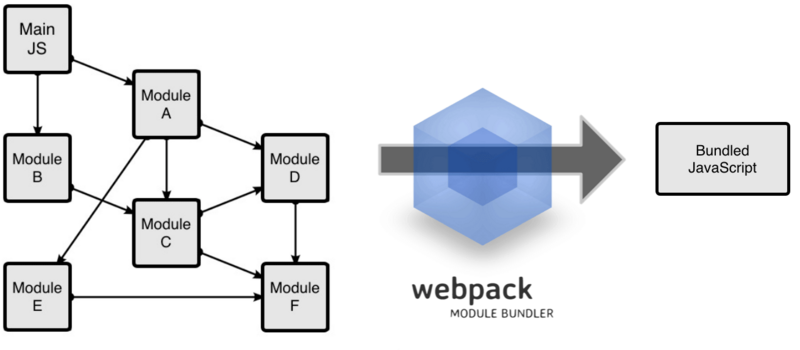
显而易见,webpack真正通过代码解析来获取依赖树,gulp可以简单理解为一个文件粒度的流操作器。
其实,啰嗦了那么多。说白了, gulp 和 webpack 根本就是两路人。gulp 是基于流的任务管理器,适合用来做构建任务的编写,对标 C++ 领域的 make, Java领域的 Ant、gradle,Clojure 领域的 boot, 它专注于定义和执行任务,打包只是恰好可以借用 流 来实现的一个动作,gulp 自身并不知道要做什么; 而 webpack 不是构建工具,它就是专注于用来解析 JavaScript 模块依赖并默认完成打包的一个可执行程序,类似于 C++ 的代码编译器, Java 的 javac。因此,他们之间的关系可以是这样的: 可以用gulp来定义和串联项目的任务,其中的某个打包任务可以使用 webpack 来完成。
如何使用webpack
命令行方式
像很多node程序一样,webpack也是既可以当做全局命令来用,也可以当做NodeAPI来用。
如果是命令方式来使用,则可以安装全局webpack
1 | npm i webpack-cli -g // 最新的4版本的webpack将cli和webpack内核进行了分离,所以你需要安装这2个包 |
或者安装在局部项目中(推荐):
1 | npm i webpack-cli --save-dev |
局部安装的方式,一般是使用 --save-dev 作为开发依赖来安装,因为webpack只是开发过程中的工具,并不是类库本身需要依赖的包,使用dev开发依赖,可以让类库的用户(调用者)在安装时免去安装不必要的依赖。
对于前端类库来说,开发完成一般还要释出一个 dist 目录和最终 bundle.js 文件发布到 npm 上,以便进行 cdn 发布或直接被调用者使用打包后的版本。例如 vue.js 的 npm 包种就有个 dist 目录,里面放置了所有可能被用到的 bundle 文件。关于如何发布 npm 包的具体细节,我们后文再讲。
上面的2个包安装完成之后,就可以使用 webpack 命令来编译 js 文件了,webpack-cli 和 webpack 分别给你提供了 webpack-cli 和 webpack 这两个命令,他们的作用是相同的。 例如 webpack-cli 这个包里面提供的一个可执行程序,全局安装会自动软链到你的环境变量目录(对 mac 或 linux 来说一般是 /usr/local/lib/node_module),局部安装的话会软链到你当前项目目录的 ./node_modules/.bin/webpack-cli。
我们现在着重说下局部安装的 webpack 命令如何调用,一般有如下的方式:
- 直接在当前目录下使用
./node_modules/.bin/webpack的路径来调起webpack可执行程序 在
package.json中的”script”字段设置一个npm script. 这时 npm 会自动在node_modules/.bin目录下寻找 webpack 命令。如1
2
3
4
5{
"script": {
"build": "webpack index.js"
}
}如果你 npm6 以上的版本,可以尝试使用使用
npx命令,该命令也会自动在node_modules/.bin目录寻找可执行程序
现在我们可以使用webpack来编译一个js代码了,比如写一段如下的代码:
1 | // index.js |
这是一段使用ES6的模块导出方式,并使用了ES6箭头函数的代码。我们执行webpack命令来编译它:
1 | npx webpack --mode=development ./index.js // webpack4增加了mode选项设置,用来指定编译目标环境;如果指定为production则默认会加载优化插件进行代码压缩 |
执行之后,会看到在当前目录下生成一个dist目录,目录结构如下:
1 | -- dist |
main.js就是编译出来的bundle(打包结果)。我们大概看下他的代码结构,是这样一个匿名自执行函数:
1 | (function(modules) { |
关于这段匿名函数的原理,我们在本文最后讲解.
webpack命令还有很多其他的可选参数,比如mode、entry、output等等。如下是加入了 watch 和 progress 选项的一个 devbuild npm 脚本命令,能实现修改源码自动打包并展示进度。
1 | "scripts": { |
更多的webpack配置,我们就不在此赘述了,下文会讲解。
命令行+配置文件的方式
通常,我们都不会直接在命令行里输入这些 webpack options 配置,而是用一个js文件(如webpack.config.js)来存储这个webpack配置。该配置文件只需简单的导出一个node模块对象即可:
1 | module.exports = { |
之后,我们可以在bash里面直接调用这个配置文件:
1 | webpack --config webpack.config.js |
也可以在npm scripts里面写入这段shell命令
1 | "scripts": { |
webpack默认会加载当前目录下名为 webpack.config.js 的配置文件,所以可以省略该配置文件名。
webpack Node Api 的使用方式
Node API 的使用方式也是现代前端工程化中比较推荐的一种做法,其自由度比较好,容易实现更多自定义的功能。比如 vue.js 官方的脚手架(备注: vue-cli 2 生成的 webpack 项目)就是使用这种方式来搭建的。
如果是 Node API 的方式来使用,一般需要局部安装 webpack, 然后通过 node.js 引用 webpack 包的方式来用。
1 | const webpack = require("webpack"); // 只需要安装webpack核心就好了 |
node.js调用webpack内核所传递的 配置对象 跟命令行调用的配置以及webpack.config.js文件的配置细节是 完全一致 的. 所以下面我们来统一讲解 webpack 的配置方法.
webpack配置详解
无论是命令行输入配置,还是 webpack.config.js 来记录和分享配置的方式,还是 Node Api 方式来加载配置。webpack 的配置都是需要学会的,而且三种使用 webpack 的方式都是一毛一样的。这里我们简单讲解下基本配置。
webpack配置文件主要分为5大部分,这五大部分的功能如下:
- entry: 定义整个编译过程的起点
- output: 定义整个编译过程的终点
- module: 定义模块module的处理方式
- plugins 对编译完成后的内容进行二度加工
- resolve 解析。例如可以在resolve中指定某些模块的alias别名
除此之外还有 resolveLoader, devtool, targets, devServer, externals, performance 等。更详细的配置文档可以参考官方配置文档:https://doc.webpack-china.org/configuration/ 本文我们只做一个简要的入门介绍
接下来,我们假设我们的项目结构是这样的:
1 | -- src |
entry
我们可以把 webpack 输入和输出写到配置文件中。例如之前命令行中的 webpack src/index.js public/app.js 就可以转换为如下的配置文件:
1 | // webpack.config.js |
之所以里面要用 __dirname 拼出绝对路径,是因为这样你的webpack命令其实在任何地方执行都是可以的(无论 node.js 的当前执行目录(process.cwd())是什么,而 __dirname 可以保证我们正确寻找到源码所在的绝对路径。另外 webpack4 之后内置了一些默认优化处理,需要根据 mode 参数来自动生效,为了开发阶段能分析打包结果,我们把 mode 设置为 false,这样目标 bundle 不会被压缩。
配置文件写好后,放置到项目根目录下,然后执行webpack命令即可,比如把package.json中配置一个build命令:
1 | "scripts": { |
在webpack中,entry可以是对象、字符串、数组类型。如何理解这3种类型呢,我们可以认为webpack的entry最终都是会转换为对象。而数组和字符串的表示形式只是一种对象的简写形式。
例如:
1 | { |
它就相当于对象形式的:
1 | { |
即当你不写bundle名称标示的情况下,webpack默认会用一个叫做 main 的名字作为你配置的入口标示。 而数组表示法:
1 | { |
就相当于对象形式的:
1 | { |
所以我们现在只需聚焦于entry的对象表示法去学习和理解。比如如下的代码:
1 | // webpack.config.js |
其中对象的属性 key 表示的是一个入口的标示,在打包后可以用于输出时当做 bundle 的文件名(这个入口及其依赖所形成的整个模块树一般叫做一个 chunk );而 value 值(如 ‘second.js’ )则表示的是这个模块入口的实际入口代码路径。
以上面的 webpack.config.js 为例,我们编写几个 js 文件。代码如下。
1 | // add.js |
我们执行 webpack --mode=development 编译得到如下文件:
1 | -- dist |
可以看到生成了 2 个 bundle,分别对应我们 entry 配置中的两个 key (即我们配置的两个 chunk 块— main 和 second)。
由于所有入口文件里都写了对 add.js 这个加法模块的依赖,即 index.js 里引用了add.js;同时 second.js 里也引用了 add.js。那么仔细看下两个 bundle 文件结果,会发现 second.js 里被打包了 add 模块和 second 自身,而 main.js 里打包了index1, index2 和 add 三个模块,同时在 main.js 里还看到一个新的模块 0,这个叫做 零的 模块是对 index1 和 index2 模块进行的调用:
1 | // main.js bundle里的模块列表。 完整代码: https://gitee.com/dreamcms/codes/0kmrxa1tp96desy4wlg5v19 |
可以看到,数组形式的入口配置,本质上会生成一个新的入口模块并依赖你配置的入口列表;从而使得你配置的所有入口都可以被执行; 也就是说有了这个模块,index1.js 和 index2.js 才能在应用程序的起点就被触发。 但是注意到代码片段中的 module.exports 只导出了index2.js,因此对于数组形式的入口配置,webpack只会导出数组中的最后一个模块,这一点在开发类库的时候要注意.
那么入口配置对象里的key有什么作用呢? 我们看到默认情况下webpack用这个key作为了输出到dist中的bundle文件名,而除此之外,当你想自定义输出的文件名时这个key就可以用作变量标识了。例如:
1 | entry: { |
那么打包后会输出app-bundle.js.
我们仔细观察上面的例子,会发现一个问题:我们两个入口 chunk 都依赖了add.js,这样打包后的 main 和 second 两个 bundle 中都各自打包了一份 add 模块,存在重复打包的问题,对于实际生产环境同一个站点来说如果是 2 个页面跳转时进行加载对应页面的独立js,这就会导致增加了js的下载体积,无法充分利用缓存。
怎样让他们公共引用的模块可以独立出来做成一个 common.js 被多个业务 js 共享呢? 可以利用一些插件实现这一点(插件的使用我们以后再讲).
output配置
这个就是bundle的输出配置了,该配置指定了如何向硬盘写出bundle,他的具体路径是相对于output.path的。
1 | output: { |
而输出的filename可以基于webpack的entry配置进行定制,例如 [name] 就表示entry的文件名; [chunkhash]表示当前这个 chunk 的 hash。
如何理解chunk呢? 我认为的 chunk 就是在entry处所指定的元素,即一个入口对应一个chunk。而 chunk 的 chunkhash 计算是跟这个 chunk 所依赖的所有模块相关的,chunkhash 是根据入口起点来计算某一个bundle的哈希的,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的哈希值。只要代码不做修改,则多次构建过程中生成的 chunk哈希 是一样的,因为模块树和模块内容没有发生变化。多个 entry 入口的 chunk 的哈希必然是不同的(只要他们的模块树是不同的)。
而采用 [hash] 计算的话,是依据 webpack 构建环境相关的,即使文件内容压根没有改变,改动了 webpack 一些环境也会导致 hash 变化。这样子可以让多个 entry 的 chunk 都采用同样的哈希,但是不利于实现客户端长缓存效果,我们通常需要使用 chunkhash。
有时候 js 里面引用了css的话,js改变可能会导致 extract-text 抽离的css文件哈希也发生变更,这时可以利用 content-hash,参考掘进
source-map
webpack有个配置项,叫做devtool, 把他配置为source-map就可以给代码生成source-map,现在的配置如下:
1 | module.exports = { |
其中source-map有多种配置的值,我选择的这种适合在生产环境,它会生成一个完整的sourcemap文件。
module配置
module配置,是为了配置webpack中进行模块加载时的行为,这也是webpack的重点,webpack进行模块加载时必须使用一些loader对不同类型的模块进行处理,所以module配置里的重点就是配置相关的loader。
从webpack2开始,loader的配置叫做rules规则配置。它是个对象的数组,每个对象是一个模块加载器,里面需要配置文件匹配的扩展名模式以及test匹配之后使用的loader,当webpack解析模块依赖时遇到匹配到的模块,就会调用你配置的loader进行处理,然后返回js格式的模块。
每个文件(.css, .html, .scss, .jpg, etc.) 都是模块,然而 webpack 自身只理解 JavaScript;所以webpack的 loader 有两个目标:
- 识别出(identify)应该被对应的 loader 进行转换(transform)的那些文件。(test 属性)
- 转换这些文件(实际上是解析为AST抽象语法树然后转换为JavaScript模块),从而使其能够被添加到依赖图中(并且最终添加到 bundle 中)(use 属性)
loader的配置语法如下:
1 | module.exports = { |
include表示哪些路径会被loader处理,他是个路径数组; exclude表示排除转换的路径或文件。 我认为,webpack发现一个模块依赖另一个模块时,先用对应的loader将各个依赖的模块转义之后,才把他们添加到了依赖图中;依赖图中的模块就已经是webpack自身能够理解的JavaScript模块(甚至本质上可以将他们看做是commonjs模块)。最终,webpack是将依赖图中的js模块再合并处理成为最终的bundle.js
resolve配置
resolve有点像C++等语言中,给编译器配置库查找的路径Lib=xxx, 也就是说webpack在执行编译的时候,如果你require了一个没有写路径的模块,webpack应该到哪里去查找模块。
对于 require('./jquery') 这种带路径的引用,webpack知道是相对于这个代码文件的同级目录下的jquery.js. 而如果你写作 require('jquery'), 那么webpack就不知道如何处理了,在node.js中这意味着是去node_modules寻找项目依赖的包中的jquery。而对webpack来说,需要通过resolve配置项告诉它寻找路径。
resolve.modules字段表示webpack的默认搜索路径,他是个数组类型 可以配置多个路径.
resolve.alias表示配置依赖文件的别名,有些文件名比较长,或者路径比较长则可以在这里处理。在vue2官方模板中,设置了一个 @ 的别名来代表src目录,所以代码中你经常会看到 @/componets 这样的路径。我在自己的vue.js的项目中,也配置了一些别名:
1 | module.exports = { |
这样,在我的Vue.js代码中如果有 require('@views/Index') 这样一句话,则webpack编译时就会发现@views是个别名,意味着 ../src/views 这个目录,确定了目录然后寻找Index,webpack此时会依次寻找extension中设定的 .js, .vue, .css, .styl, 发现有一个Index.vue,则认为你是require了一个叫做Index.vue的模块,然后发现是vue扩展名,则根据上文讲到的module rules中的配置调用 vue-loader 来处理这个Index.vue模块。
快速理解webpack打包后的bundle文件结构
上文讲到了webpack编译后的main.js是一个自执行的匿名函数,这里我们简单剖析下这个匿名函数。它完整一点的代码如下:
1 | (function(modules) { // webpackBootstrap |
这个匿名函数的实参是一个Object对象,对象里就是各个js业务模块;而匿名函数内部就是webpack的脚手架代码webpackBootstrap(我也称之为webpack模块运行时)。它主要做了以下几件事情:
- 实现了 webpack_require 函数用于加载模块
- 通过一个installedModules对象,实现了模块缓存(module cache)。这样便可以跟node.js里模块机制的缓存表现一致(模块只加载运行一次)
- 用commonjs的方式对源码中的 esmodule 进行了hack。(webpack在不适用babel的情况下内置了一个esmodule的转换器;注意: 在不使用webpack的场景下要想使用esmodule那可是必须要亲自用babel转换的哦,比如你在写node.js时)
- 加载并执行了入口模块(如果是多入口,则在bundle里会自动创建一个新的合并起入口来的模块)
我们来仔细看下这个模块的列表,他的结构是这样的:
1 | { |
分析下上面这段编译后的模块代码: 在这个例子中 我们的入口函数里用 export default 导出了一个函数test, 而我们看到webpack编译后的代码中并没有直接使用 __webpack_exports 去导出这个函数,而是如上面的代码片段所示 用 __webpack_require__.r 这个函数修饰了一下 _webpack_exports, 然后再把导出的变量赋值给了 __webpack_exports__的default属性.
看看这个 __webpack_require__.r 函数做了什么:
1 | // define __esModule on exports; 在exports导出对象上定义__esModule属性 |
我们注意到webpack在这里做了两件事情:
- 给exports导出对象添加了
Symbol.toStringTag属性,属性的值为’Module’。这是ES6给对象新增的一个内置的属性,这个属性可以决定对象调用Object.prototype.toString方法后返回的[object XXX]里面的类型名字. 具体细节可查看: Symbol.toStringTag - 给exports对象添加了一个普通的属性
__esModule, 属性的值为布尔值true
之所以这个模块的导出对象exports被修饰后再return,是因为我们编码时使用的ES6的exports导出语法. 而webpack的模块运行系统采用commonjs的模块导出方式,所以模块间引用需要兼容(我把它称之为用commonjs方式hack源码中的esmodule的写法); 如果你编码使用的commonjs模块语法,那么webpack就无须做任何修饰了。
为了了解webpack为什么对ES6的模块导出要挂载在exports.default上面,我们可以来一个简单点的1+1算术的模块调用的例子看下:
1 | // add.js |
执行编译命令后得到如下结果:
1 | (function(modules) { |
如果把add.js改成ES6的导出语法:
1 | export default add = function(a, b) { |
我们发现编译后的add模块变成了使用 exports.default 的方式导出:
1 | import add from './add' |
但是当我们在浏览器中引用这个js使用时,发现报错了:
1 | Uncaught ReferenceError: add is not defined |
原因就在于: 虽然add模块已经被webpack挂载在exports.default属性上导出,但是index.js去引用add模块的时候,还是使用的commonjs写法,编译后便采用 __webpack_require 函数去引用的,该函数的实现只能兼容commonjs方式导出的模块,因为我们看到他的实现代码里就是执行目标模块并把目标模块里的module.exports返回出来(但add模块是把模块接口挂在了module.exports.default上面),因此index.js使用add时必然会报错.
1 | // webpack_require实现片段 |
因此,__webpack_require_ 函数就是去导入 commonjs 类型模块的一个函数,而不能导入 ES6 default导出语法编译后的模块。所以我们得出结论,在webpack的打包系统内编码时,我们需要保持一致的模块导入导出方式。所以我们把index.js代码中导入add模块的方式修改成ES6的方式:
1 | // index.js |
编译后的index.js模块变成了这样:
1 | { |
可以看到,ES6的方式去import一个ES6编写的模块时,webpack就能正确进行编译了。编译后的代码可以正确的去获取修饰后的add模块(读取add模块导出对象上的default变量)。
对于非default导出的ES6导出方式,webpack会编译为挂载到exports对象上的属性. 这种情况被调用模块会把导出内容挂载到commonjs导出对象上,调用者会直接调用导入模块的对应属性。我们看一个非 default 导出方式的 add.js 和 index.js的编译结果:
1 | './add.js': (function(module, __webpack_exports__, __webpack_require__) { |
像这种情况下,调用者实际上可以使用 ES6 和 commonjs 的方式来引用add.js中的属性。不过,我们强烈建议凡是要使用ES6 module,就全部使用 esmodule,不要交叉使用。
最后,我们再来看下AMD模块编写方式在webpack编译后会变成什么样子:
1 | // add.js |
看下编译结果:
1 | { |
可以看到 AMD 的方式编译结果变得稍微难读了一点; 不过分析之后发现,其跟 commonjs 写的源码的编译结果是类似的(因为它的模块导入导出方式没有 esmodule 那么复杂)。所以AMD编译后的模块原理按照 commonjs 的方式来理解即可,没有那么难。
总结
本节我们学习了一些webpack的基础概念并大致看了下webpack的基本配置字段;最后分析了bundle文件的基本原理。比较啰嗦但应该有点收获吧。
在下一节我们介绍webpack中一些在解决实际问题中常用的loader。
Refer
英文官网
中文文档
一小时包会-webpack入门指南
什么是webpack,为什么要使用它
webpack高级-插件的使用,webpack1.x
webpack是答案吗
入门 Webpack,看这篇就够了