AI之-一个完整的宝宝起名AI应用编写
效果
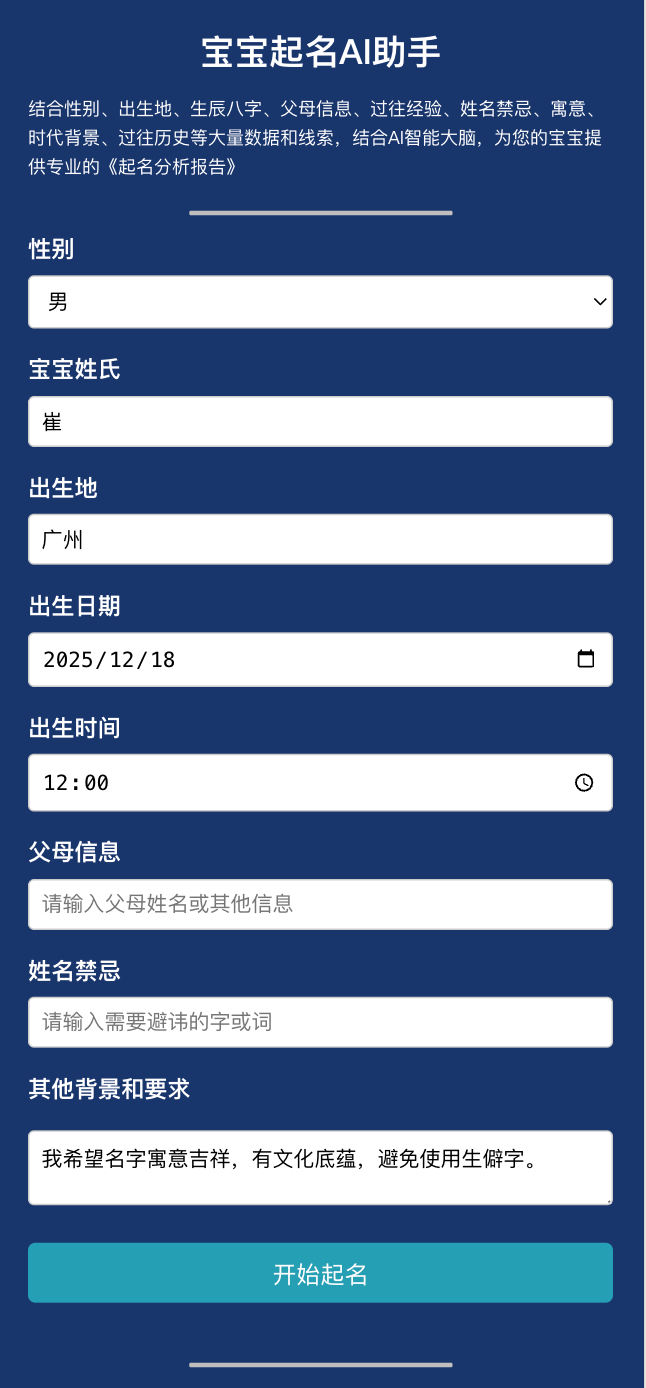
能力:
- 基于性别、姓氏、出生时间、忌讳字等基础客观信息,查询出用户的生辰八字、天干地支、属相等信息。
- 用AI给用户生成一份起名建议报告:命理综合分析、姓名候选列表、各个名字的分析、宝宝未来预测、诚挚祝福
历史记录传递
历史对话记录有时候会被称作“context”。但其实广义的context上下文窗口是包含整个跟大模型交互的所有内容了(例如系统提示词等等)。
不过我们大概知道这些概念的区别就行了。直到什么场景下说出来的时候他代表什么即可。
关于如何给大模型传递历史记录,我们在工程上需要考虑:
如何保存历史记录
如何传递历史记录给大模型
历史上下文过多时候如何处理。
第一上下文太多会撑爆窗口,第二他会浪费token资源,第三也会引起LLM思考性能下降。
思考模式实现
生产环境:考虑两阶段推理,可控性更好
复杂推理:使用ReAct或思维树模式
https://yuanbao.tencent.com/chat/naQivTmsDa/3c3fdd22-79c6-4163-81c7-6f8494d517b0
RAG检索
假设一次提问后,ai的回答是2000个字的回答,假设里面引用了10处我博客的内容,10处内容分别对应到我8篇博客文章。
但我在想,你rag检索的时候通常不是只检索top3么,那岂不是无论怎样你只会给ai大模型3个检索结果片段? 那如果我的提问问题就是希望基于我博客里的一些内容来回答,仅仅靠3处rag向量结果那岂不是非常单薄?意味着大量内容都是ai编造的,只有3句话是真的来自我的博客。是这么理解吗?一般怎么解决这种问题的—即要怎样让ai的回答都是基于我真实博客内容的回答,而不是仅仅有3句短短的句子是来自我的博客。
你的直觉非常敏锐,这正是 RAG(检索增强生成)从“玩具级”迈向“生产级”时最核心的工程痛点。
如果你只是死板地取 $k=3$(Top-3),而你的问题又很宏大(比如“总结我过去一年对 React Fiber 的所有思考”),那么 AI 确实会面临“巧妇难为无米之炊”的尴尬,导致回答内容要么单薄,要么开始胡编乱造。
在实际的 R&D 工程实践中,我们有四种标准方案来解决“信息量不足”的问题:
1. 动态调整 $k$ 值与 Rerank(重排序)技术
不要只检索 3 个片段,先“海选”再“精选”。
单纯的向量检索(Vector Search)是基于语义相似度的,有时候它找得并不准。
- 做法:初筛阶段我们取 $k=50$ 甚至 $k=100$。
- 重排序(Rerank):引入一个专门的 Reranker 模型(比如 BGE-Reranker)。这个模型计算量大但极度精准,它会从这 50 个片段里,重新打分,选出最核心的 5-10 个片段。
- 效果:这样喂给大模型的数据质量会大幅提升,信息量也从“3 句话”变成了“3000 字”的高浓度素材。
2. 父子文档检索 (Parent Document Retrieval)
这是解决“断章取义”的神技。
- 痛点:为了检索准,我们通常把博客切得很碎(比如 200 字一段)。但 200 字往往讲不清楚一个复杂的逻辑。
- 方案:
- 我们在数据库里存两套:子片段(200字,用于检索)和父文档(2000字全文或大段落)。
- 当系统通过子片段命中目标时,它不把子片段给 AI,而是根据元数据(Metadata)找到它所属的父文档全文喂给 AI。
- 效果:AI 拿到的不再是碎纸片,而是逻辑完整的整页书。
3. 混合检索 (Hybrid Search)
向量检索(语义)和 关键词检索(BM25)的结合。
- 如果你问的是“Fiber 里的
workInProgress变量”,向量检索可能因为语义模糊找不准,但关键词检索能精准定位到所有出现过这个变量的代码段。 - 将两种检索结果融合,能保证 AI 既懂你的“意思”,又拿到了“硬核数据”。
4. 提示词工程:强制“基于事实”
如果 AI 还在编造,那是因为你的 System Prompt 约束力不够。你需要给它戴上“脚镣”:
严格指令:
- 你只能使用【参考资料】中的信息回答。
- 如果资料不足以支持回答,请直接说“我的博客库中目前没有关于此细节的记录”,严禁发挥。
- 如果发现资料中有冲突,请罗列不同时期的观点。
真实世界的工程配置建议
既然你的语料库有 150 万字,你可以参考这个配置逻辑:
- 切片策略:采用 300-500 字/片段,设置 10% 的 Overlap(重叠)。重叠是为了防止某个核心知识点刚好被切断在两个片段中间。
- Top-K 选择:不要吝啬。现在的 API 窗口很大,你可以尝试 $k=10$ 到 $k=15$。15 个片段大约 5000-8000 字,这对于 GPT-4o 来说处理起来非常轻松。
- 引用校验:在输出中强制要求模型给出
[原文片段 ID]。这样你在前端可以做个校验,如果没有对应的 ID,就通过 UI 提醒用户“部分内容为 AI 生成”。
总结
RAG 不是为了限制 AI 的发挥,而是为了给它的发挥提供足够厚的“地基”。 当你的 $k$ 足够大(比如 $k=10$),且每个 $k$ 都带有丰富的上下文(Parent Document),你会发现 AI 写的 2000 字回答里,每一段都能在你的博客里找到原型。
这种“喂饭”的方式,你觉得在你目前的后端逻辑里,实现 Reranker 或者父子文档检索,哪一个的开发成本更高?
关于思考的耗时问题
https://gemini.google.com/app/869c983d2f237fd9
- 强制截断思考:使用 stop 参数
- 看看降低一下思考深度(或胡思乱想参数):top_p和temperature
- 提示词层面的“思想钢印”给他设计几个步骤不让他多做。但这个其实不太好。
- 感觉可以设置max_token总输出大小。既然输出的总量定了,那么他模型他自然会知道自己思考的量肯定也知道要减少。但这玩意也可能会造成咱最终的成果输出内容变少。哎。
前端的渲染
流式markdown实现
思考阶段输出
回答阶段输出
多模态?
##
https://gemini.google.com/app/8cbe78a7f6a5be80
生图模型? SB绘图
https://juejin.cn/post/7238510633967304762
是不是可以用它来绘制一个宝宝的照片或者吉祥物啥的?
或者绘制宝宝名字的毛笔字艺术字?
ocr和视觉理解模型?
https://gemini.google.com/app/70abd1996f83e9bd
ollama上都有一些。可以用来识别图片是在干嘛,以及甚至ocr识别图片内容用到其他逻辑里去吧。而且这些本地模型是免费的哦。
调用本地ollama-内网穿透的艺术
家里的模型要sse流式输出内容的话,如果让他走腾讯云服务器中转一遭其实:”带宽流量占用还相对挺多的“,且”中转多一遭,对于实时push类的消息总归是多了一道延迟“,且他是长连接不断开”这句柄的占用很容易消耗我腾讯云服务器上本来就很频发的内存和cpu“。
于是其实这场景比较适合p2p到家里。于是我的webrtc p2p到家里的双工通道能力就能用上了。
如果模型要输出图片,或者用户要传递图片给家里的话,或者生成pdf给用户下载分享的话,那就用webrtc二进制传输呗,反正也有createObjectUrl的方案:https://gemini.google.com/app/4dac3a3130314562,也有下载文件的方案。