AI之-玩转claude
是啥
竞品有codex:它是 OpenAI 为了对标 Anthropic 的 Claude Code 而推出的桌面客户端。
codex的能力:
多代理并行: 你可以同时开好几个任务(Thread),一个让它写前端,一个让它调后端,它们互不干扰。
内置浏览器: 它自带一个浏览器窗口,AI 可以直接打开你的 localhost:3000 调试页面,看到报错直接自己改代码。
跨 App 协同: 它可以读取你的 PDF 文档,然后根据文档内容去 Xcode 或 VS Code 里改代码。
那copilot呢?
copilot只是个智能助手?感觉也能干codex和claude的事情。
都有哪些
从ccSwitch这段描述中就能看到有哪些:
CC Switch 可以帮你在 Claude Code / Codex / Gemini CLI 的多个供应商之间一键切换。如果你之前已经配置过这些工具,CC Switch 会自动把现有设置保存为名为 “default” 的供应商,保证你的配置不会丢失。
列表里还预置了 “官方(Official)” 供应商,随时点一下即可切回官方默认配置。切换前 CC Switch 会自动把当前配置备份回 default,可以放心来回切。CC Switch 就是这样工作的 😊
https://www.youtube.com/watch?v=srUeEjCjfNE
ccswitch是啥
是统一管理不同cli里面的mcp配置和apikey配置的。
https://github.com/farion1231/cc-switch
模式

- plan模式就是他会基于你的问题去创建一个有目标说明,有步骤说明,有如何验证的一个计划markdown,然后你确认后他再按照markdown执行。
- ask before Edit。就是不做计划,反正就按你的要求去做。但是写操作之前都要先询问你一下,让你看到diff确认后再写。
- edit automatically。就是自动给你改也不问你。
计划模式
使用计划模式提要求的时候,他会给你制定一个计划书。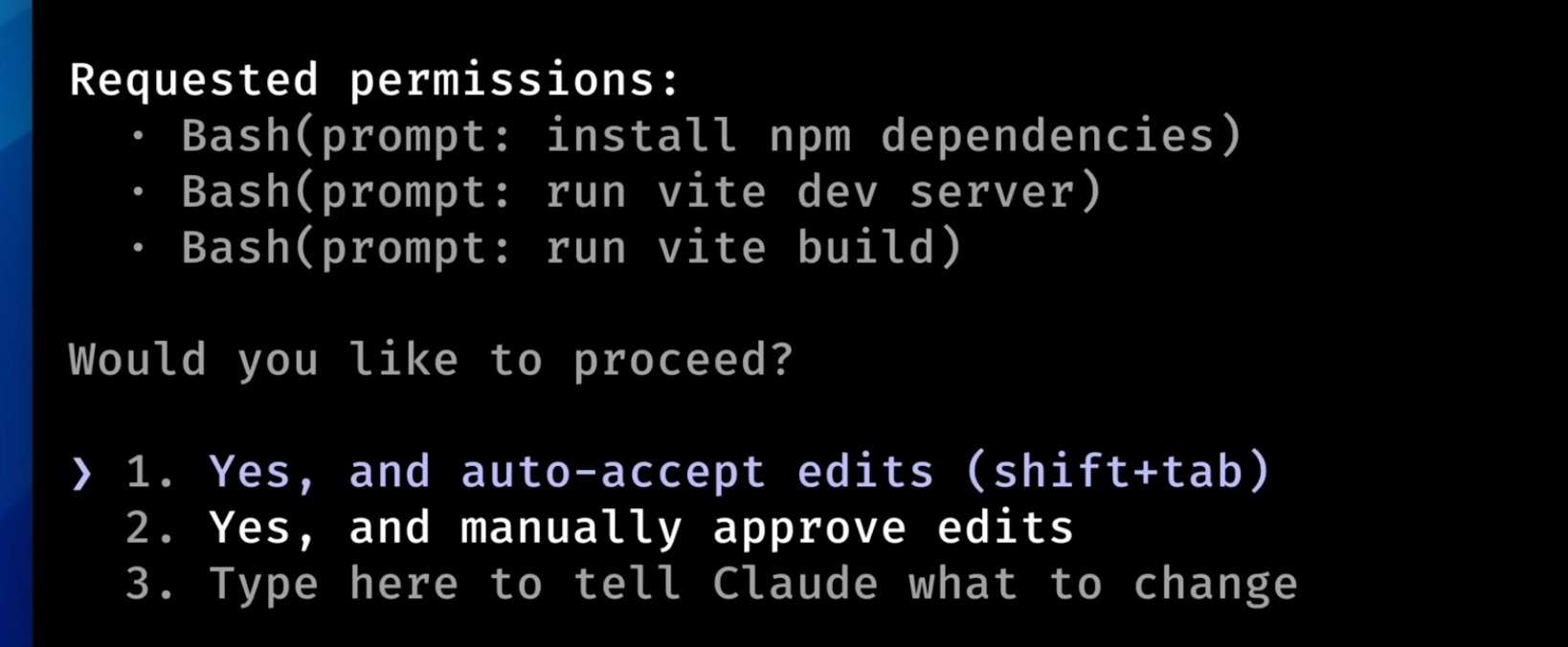
当给你做好了计划他会提问你这些问题: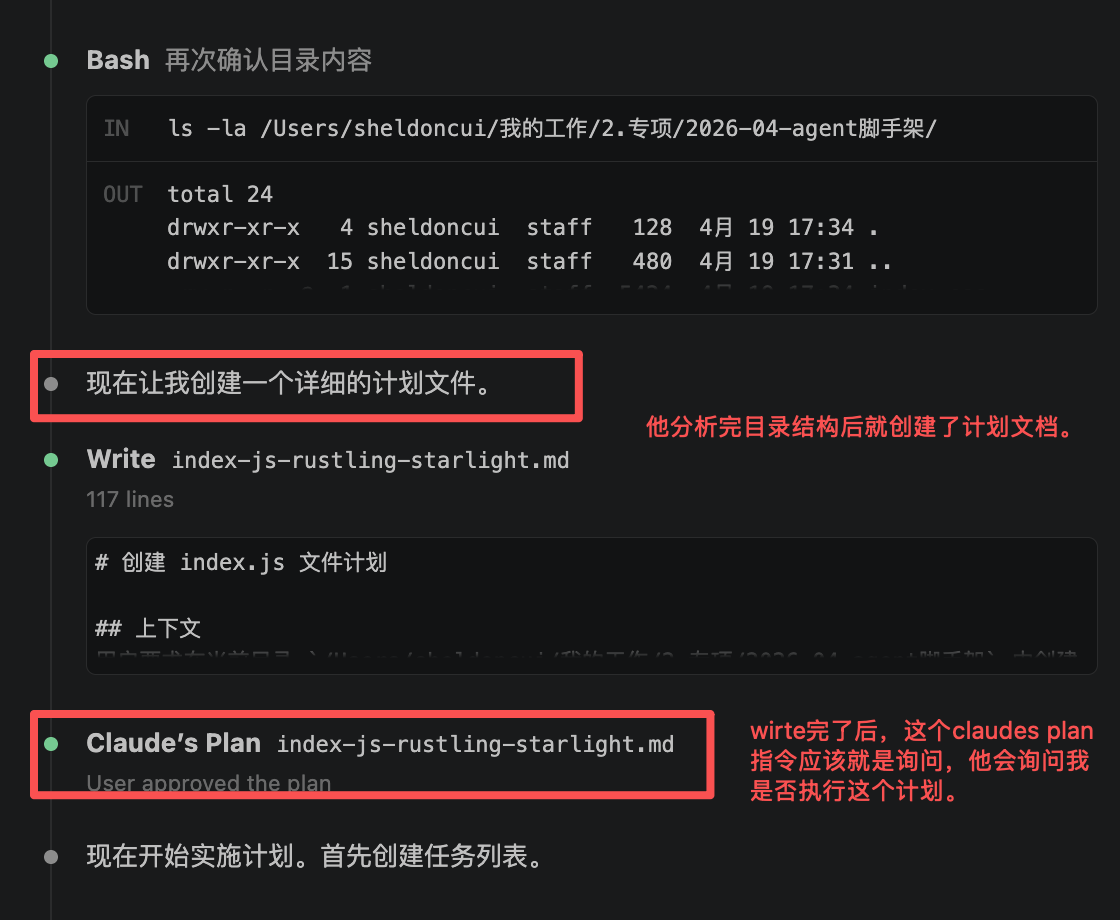
我们可以选择:
- 同意执行,进入自动edit模式,不需要找我确认
- 同意执行,但是每次执行他要找我确认。
- 不满意。输入一些要求继续改计划。
注意:同意让他自动edit模式执行仅仅是同意他写文件,并不代表他能任意执行bash命令(例如创建目录、npm install等等),发生命令执行的时候claude依然会向你请求你的同意的。要想让他自动执行bash你得在启动claude的时候开启危险模式。。。
命令
/init
这个是创建claude.md文件,他是项目的描述。你会发现执行这个命令的时候,他会分析读取所有文件。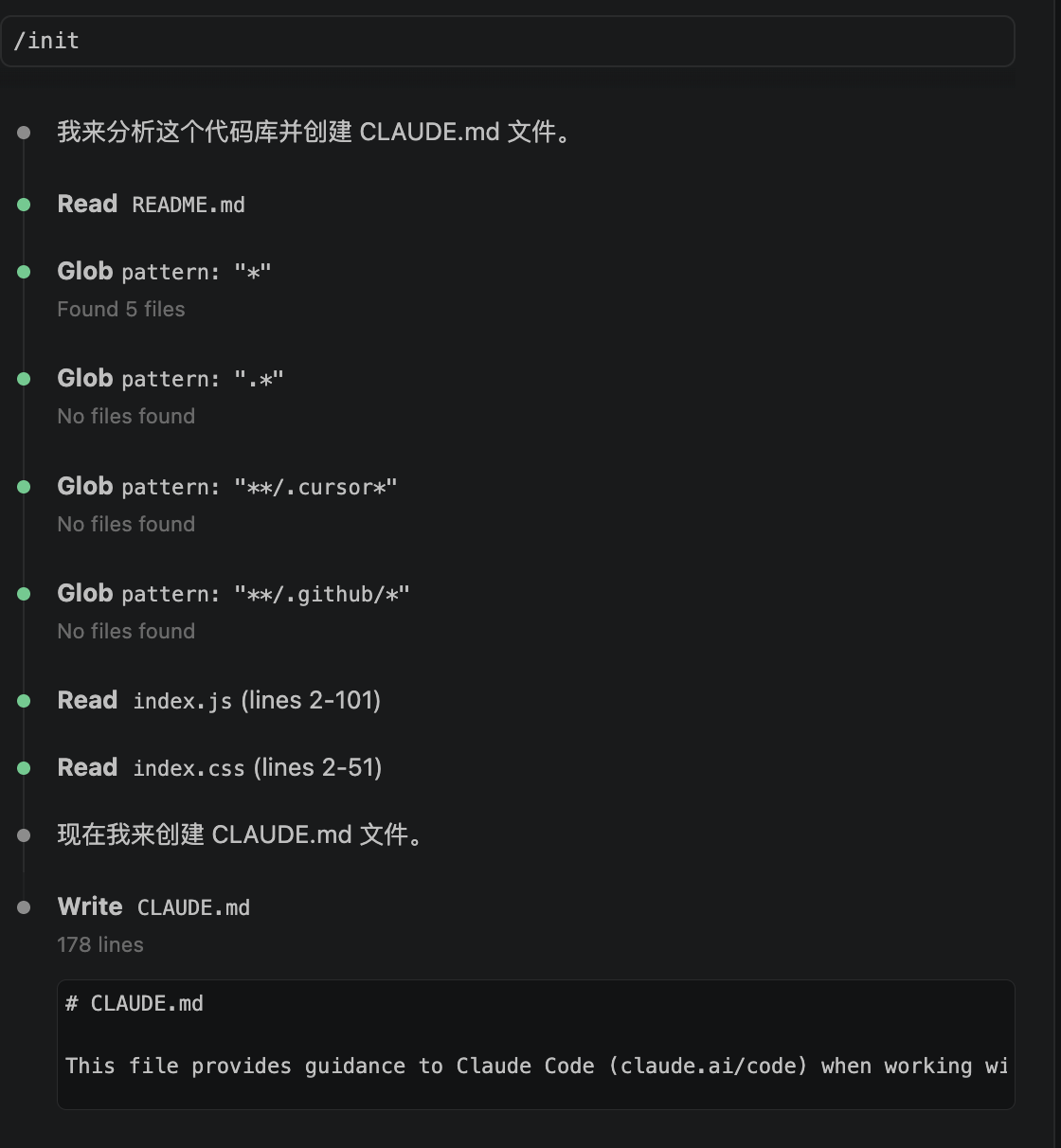
可以看到他把代码架构以及关键细节都给你研究明白了: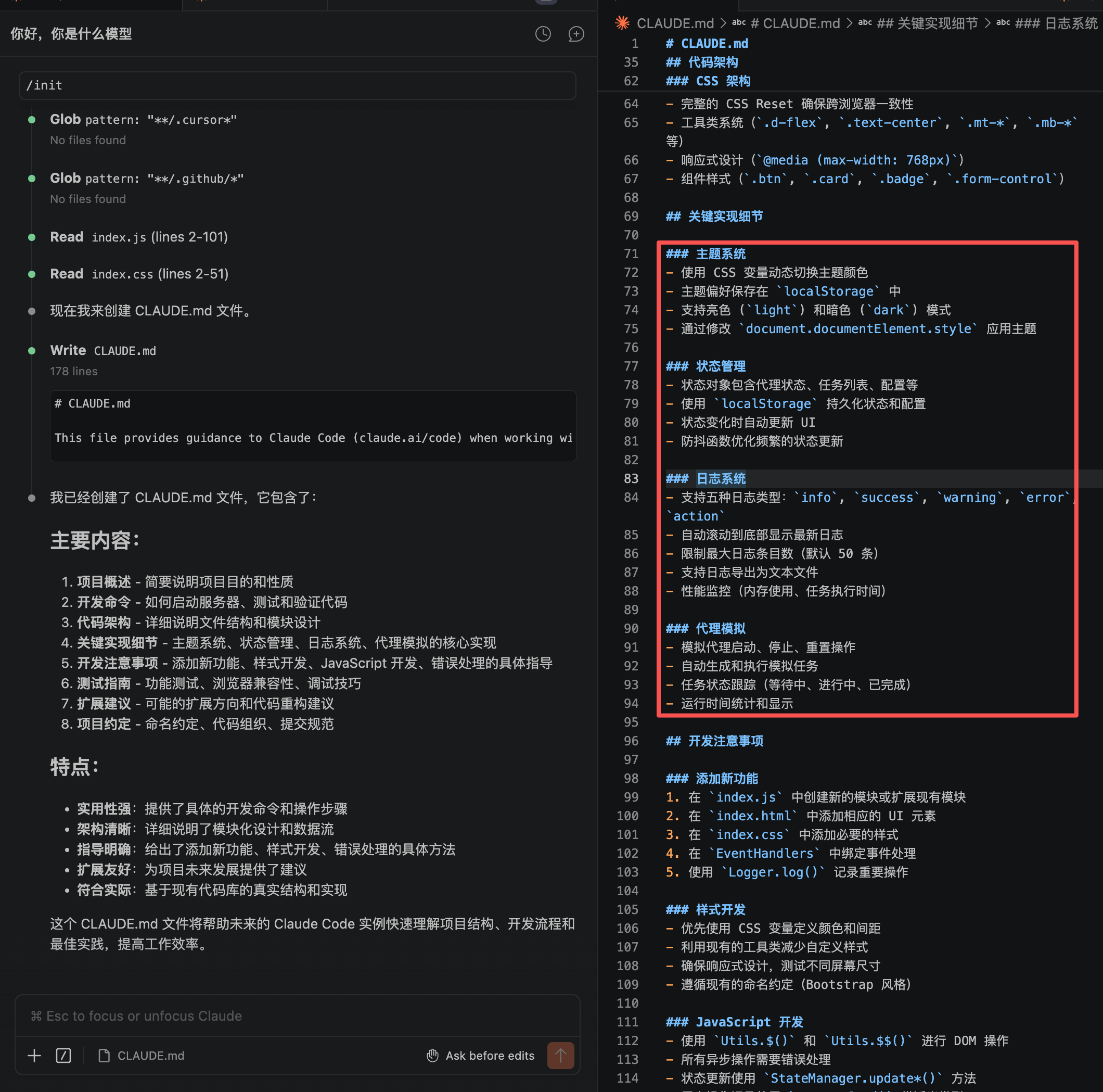
最佳实践: 你应该手动维护这个文件。在里面写上:“本项目登录入口在 /login,由 AuthContext 统一管理状态”。这样 AI 以后处理逻辑时,不需要翻遍所有文件,直接看 claude.md 就懂了。
使用bash命令
1 |
|
提问的结构化
审计与验证
运作原理
背后的“大脑”是如何运作的?
这种工作模式的核心架构被称为 ReAct (Reasoning and Acting) 范式。模型在执行一个带反馈的循环(Loop)。
核心逻辑:思考 -> 行动 -> 观察
Reasoning(思考): Claude 接收到你的指令,先在大脑里拆解步骤。
Acting(行动): 它发现自己不能直接回答,需要看一眼你的 index.css。于是它调用一个名为 read_file 的工具(Tool Call)。
Observation(观察): 系统把文件内容喂回给 Claude。它看到内容后,产生了一个 Observation 节点,也就是你看到的“我已经了解了项目结构”。
coding指南
项目级别的上下文
Project-Level Context Injection” (项目级上下文注入),能极大减少 AI 生成代码后的二次修改成本。 claude.md以及claudrule.md。
提问要规范
提问要遵循 “背景 + 目标 + 限制” 的原则。
错误示范: “给我写个登录逻辑。”(AI 会随便写)
最佳实践: “基于目前的 auth 模块(背景),帮我实现一个带验证码的登录逻辑(目标)。注意:校验逻辑要写在 hooks/useAuth.ts 里(限制)。”
善用思考链
其实就是跟ai互动让他通过互动来思考出我们期望的”规划—>确认—>执行“。先引导他思考并做出规划,然后咱们再确认,再让他执行。而不是直接按我说的执行。
不要只说“帮我写个 index.js”,而是在后面加一句:“请先分析项目结构,列出实现步骤,确认无误后再写代码。”
善用plan计划模式
改动文件比较多的时候,考虑切到plan模式。
当 Claude 弹出你之前看到的 xxx-plan.md 时,千万不要直接点确认。
最佳实践: 快速扫一遍计划。如果它计划修改的文件超出了预期,或者遗漏了某个关键文件,直接在聊天窗口回它:“计划里漏掉了 index.css 的更新,请加进去”。
这是一种 “Human-in-the-loop” (人工反馈闭环)。AI 执行前必须经过逻辑审计,这叫 “Prompt-level Gating”。
善用at,善于缩小问题范围
在聊天框里用 @Files 或 @Folders 明确告诉 Claude 应该看哪些文件,别让它自己去瞎猜目录(节省 Token,提高准确率)。
当然了如果是某个需求涉及多个文件,你也没必要自己at给claude,毕竟claude自己也有自主检索能力。他有自己的“RAG(检索增强生成)与 Context Window(上下文窗口)管理”技术,且他大概会通过bash搜索关键词以及查看文件代码后再去按图索骥的方式,以及通过读取你claude.md的方式找到对应要修改的东西的。
插件
他是hook、subagent、skill、mcp的一个合起来的包。
effors的含义和原理
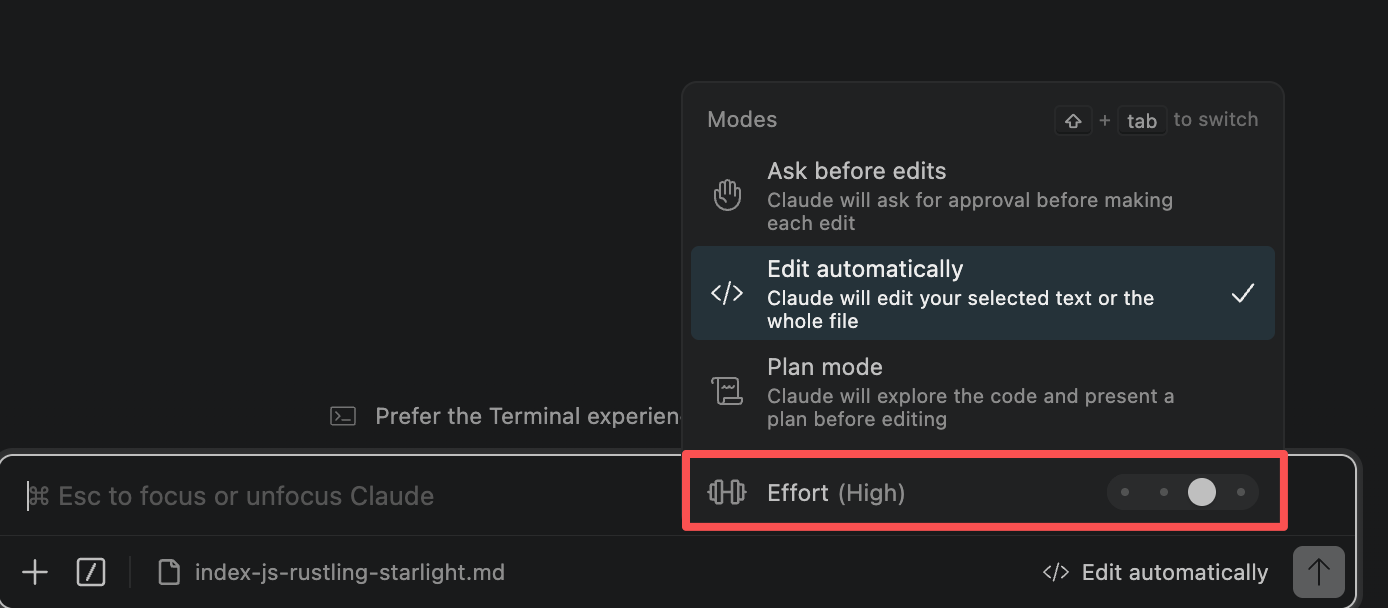
简单来说他代表了让模型思考的深度和长度。思考越多当然也会造成 消耗token越多、GPU机器给模型思考分配的内存空间越多、思考时间也越长、回答的肯定也相对越准确(当然简单问题则反而容易钻牛角尖或浪费token)。
因此,碰到类似如下复杂任务时候,我们尽量把efforts调整到max:
复杂 Agentic 任务: 当你让 Claude 自动去你的 Monorepo 里修改多个关联文件,或者需要它进行反复的工具调用(Tool Calling)时,Max 能够显著降低它在中途“迷路”的概率。
底层架构设计: 比如你正在优化的 Node.js 系统架构,或者需要它推演 React Fiber 节点的更新时,Max 会让它在输出前进行更严苛的自检。
efforts的底层原理
Claude 的 API 确实在 2026 年(即当下)引入了原生的推理控制参数,这和 DeepSeek 这种“目前只能靠 Prompt 引导”的模型有着本质的区别。
在 Claude 的环境下,你在插件里看到的 low/medium/high/max,背后对接的是 API 协议中真实的原生拨片。与 DeepSeek 不同,Anthropic 在其最新的模型(如 Claude 4.7/4.6 系列)中引入了一个名为 effort 的顶级 API 参数。它的本质: 这是一个原生的权重控制。它直接告诉模型内部的“推理控制器”,在生成答案前,愿意分配多少 Token 预算给 Extended Thinking(扩展思考)。它是 API 控制的: 当你在插件里选择 Max 时,插件发送给 Anthropic API 的 JSON 里会包含 “effort”: “max”。
这是一个物理层面的硬参数。模型在接收到这个参数后,会物理性地调高其思维链(CoT)的深度和广度。
当我的claude通过ccswitch配置了走deepseek的模型的时候,他efforts配置成hight/max之类的时候,其思考必然是走的deepseek-reaseoner的推理能力的模型,然而deepseek api并没支持类似efforts这样的硬件思考参数,于是claudecode底层大概率是通过提示词来告诉deepseek思考的简洁和复杂的。例如:
- low。可能就直接调用deepseek的v3模型,非推理模型肯定就不会think了。
- medium。可能就告诉模型“请以最快速度回答,忽略不必要的思考步骤,直接给出结论。“。
- max。可能就会告诉模型“请进行极度详尽的思维链推导(Chain of Thought),考虑所有边缘情况,反复检查逻辑漏洞,在给出答案前进行彻底的自我博弈”
虽然你可以通过提示词(Prompt)诱导模型写出思维链,但那只是“表现层”的模仿。Claude API 原生的 effort 参数控制的是“算力预算” 以及 推理 Token 的配额: 赋予模型生成成千上万个隐藏思考 Token 的权力。在高 Effort 模式下,模型会降低对“概率最高”字眼的盲从,转而支持更严密的逻辑推导,哪怕那个逻辑推导比较费劲。
.claudignore
上下文精简的艺术
- 文件的“引用控制”(最直接的方法)
不要把整个项目丢给它。
手动控制: 在聊天框里,只 @ 那些相关的核心文件。比如你改 React 组件,只 @ 这个组件和它的 types.ts。
利用 .gitignore 或 .claudignore: 插件会自动忽略这些文件。把你的 dist、node_modules、巨大的 package-lock.json 统统屏蔽掉,能省下巨额的输入 Token。
- 现在的coding插件通常会先扫一遍你的项目生成索引。
如果你在设置里发现 “Context Limit” 这个选项,它就是你说的那个“控制输入”的参数。
如果你调低它,插件在读取代码时会变得“挑剔”,它只选那些它认为最相关的代码片段(Chunk),而不是全文读取。
发现模型开始“糊涂”时,点一下 “New Chat”。这会瞬间把输入上下文清零
插件的 RAG 机制(检索增强生成)
这是目前处理大型 Monorepo 的核心逻辑:
扫描: 插件把项目切成一万个小块。
搜索: 根据你的问题,搜索出最相关的 10 个代码块。
拼接: 只有这 10 个块(可能才 2k Token)会被作为输入发给模型。
结论: 这样你即便有 100MB 的代码,模型实际看到的输入也被控制在了你设定的预算内
为什么小龙虾的skill还能连接飞书之类的
claude可以吗。远程干活。