AI之-知识初探
AI概念
LLM: 大语言模型。google团队2017年提出的。openai2022年实现成可用级别的大模型。大模型内部是transformer架构,可以认为是接收一坨数字向量,然后输出一坨数字向量,内部的计算过程就是一坨“数学矩阵运算”。
token:要理解token得先理解tokenizer(下文会讲),tokenizer对人类输入进行token化,对LLM输出的token进行文字化。这里把你的自然文字切分成的多个词元就是token的概念。
context: 上下文。是指的跟大模型交互过程中的“输入内容-对话历史”、“输入内容-用户问题”、“输入内容-工具列表”、“输入内容-systemPrompt”、“当前输出”。这些都是上下文。
DDD: DDD是“道”,它关注如何理解和建模复杂的业务世界。DDD 不是先写文档再编码,而是通过与领域专家持续交流,将业务规则直接翻译成代码中的类、接口和方法。推荐使用:业务复杂度高、规则多变、团队规模较大,且需要长期维护的核心系统(如电商、金融、ERP 系统)。不推荐使用:简单的增删改查(CRUD)系统,或者业务逻辑非常薄的工具型项目。使用 DDD 会增加大量的前期建模成本,导致“过度设计”。DDD 的本质是“分而治之”,通过划定边界来处理复杂性,通过建立贴合业务的领域模型来降低认知负担,使代码成为业务的“文档”。
SDD:Spec-Driven Development,其核心思想是规范即代码spec as code。即人类是负责编写规范,ai(类似于编译器)把他转译成代码。其实我觉得如果把ai转译+编译器编译都当做一个透明层来看的话,其实就等同于咱们人类编写规范然后ai构建成二进制机器程序来执行了。 在这个SDD下,ai就可以理解成编译器,规格文档就是源代码。
Vibe Coding:Vibe Coding(氛围编程):早期AI编程模式,通过详细提示词让AI一次性实现功能,但存在代码延续性差、风格不一致、团队协同性差等问题
RAG:向量数据库。用于存储文本片段(大概几十个字几百个字为一个片段)的向量值,然后可以提供检索匹配相似度top N的文本片段的能力。主要用于知识库检索。
prompt engineering: 提示词工程。主要就是如何把问题写明白给到大模型。随便大模型猜测你意图的能力越来越强,现在已经不太提这个词汇了。
tools工具:是指的一个可以被调用的能力(例如函数或远程服务)。大模型(或者说agent平台)用来感知和影响外部环境的函数。
MCP:model context protocol。为了解决各个平台编写tool的规范不一致的问题,各个公司统一了一个标准的编写规范,就像npm包规范一样。
agent: 代理智能体,能够自主规划和自主调用外部工具直至解决用户问题的的程序/平台。
skill:给agent看的一个说明文档。规定做事步骤和规则。
思维链:Chain of Thought。 当时23年左右的时候有人发现如果给大模型提问的时候末尾加一句”请充分思考后再回答“则对输出很有帮助,于是后来大模型就直接把这推理能力加入到模型本身能力里面去了。deepseek-reasoner的模型就具有这个能力,v3则不需要思考。而gpt的模型即使5.6支持思考他也不会把思考过程暴露出来,只是会暴露个思考摘要。
- 它是思维链,但它是“强化版”的
早期期的思维链主要是靠提示词(Prompting)触发的。比如你告诉模型“请一步步思考”,它就开始像模像样地写步骤。
而现在的“思考模式”(尤其是像 OpenAI o1 或 DeepSeek-R1 这种):
不仅是写步骤: 它包含了自我纠错(Self-Correction)。你会发现它思考到一半可能会说“等一下,这个逻辑不对,我重新换个方法”。
搜索与回溯: 传统的思维链是一条直线走到底,而思考模式可能会在后台尝试多条路径,发现此路不通后再折返回来,这在算法上引入了类似 MCTS(蒙特卡洛树搜索) 的机制。 - 训练方式的质变
过去的 CoT: 模型是在模仿人类写的“解题过程”语料。你给它看一万个数学题的解题步骤,它学会了这种说话的语调。
现在的思考模式: 模型是通过强化学习(RL)自己悟出来的。开发者不再教它怎么思考,而是给它一个难题和最终答案。模型在后台疯狂尝试,只要答对了,这种思维路径就会被奖励。久而久之,它形成了极其高效、甚至人类都难以完全理解的内在逻辑。
LLM
发展史:
- 2022年11月,gpt3.5
- 2023年3月,gpt4
现在Claude、gemini后起之秀都已经登上舞台。
LLM的原理是transformer架构,暂时我不太理解其底层原理,但是从应用层面我们可以知道他的表现是用于生生文本结果的。
然后他的基本运作逻辑类似于“成语接龙”,大概是:
- 接收到用户提问例如“我的博客怎么样”
- 大模型拿着“我的博客怎么样”去经历他的transformer一系列处理,找到概率最高的一个接龙词汇“特别”。
- 接下来大模型继续把“我的博客怎么样?特别”再次输入大模型进行相同的动作,这次可能得到了要接龙的“棒”这个词。于是结果变成了“我的博客怎么样?特别棒”
token是什么
要想理解token就先理解tokenizer工具。
tokenizer:是文字编码数字以及数字转文字的工具。
所谓文字就是用户提问的自然语言,所谓数字就是大模型要看的tokenId的列表,例如“我的博客怎么样”,最终交给LLM的可能是[54, 36, 33, 10]这么4个数字。每个数字就是叫一个tokenId。
那么啥是token呢?
其实上述自然语言到tokenId的过程中,首先要做一步叫做切分token,即把“我的博客怎么样”切成“我|的|博客|怎么样”,然后每个切分的文字片段就叫token(央视不是还给起了个名字叫“词元”)。之后这些词元列表,再把每个词元映射成一个数字(tokenId),于是就变成了tokenId的列表“[54, 36, 33, 10]”。而大模型最终吃进去的就是tokenId列表。
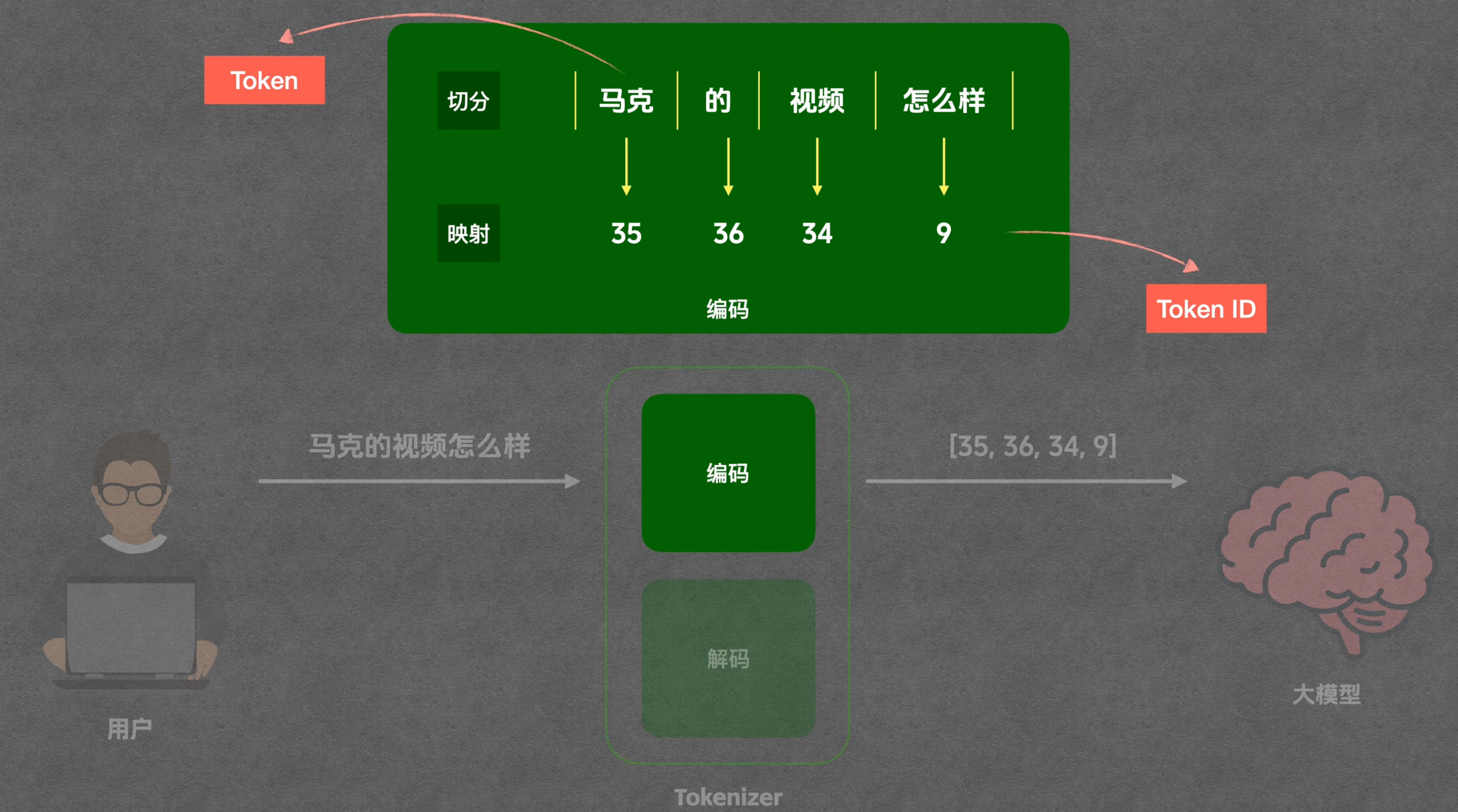
然后大模型每次思考吐出来的结果则是一个tokenId,例如[37]。 然后tokenizer工具再把这个tokenId转成token,例如转成了“特别”。
由于大模型还没有输出完毕(例如大模型内部他会继续拿着“[37]”跟之前的提问“[54, 36, 33, 10]”拼起来继续transformer运算),于是大模型又吐出来一个“[49]”, 然后tokenier继续对49进行解码成token,解成了“棒”。
于是从用户侧先看到返回了一个“特别”,然后看到返回了一个“棒”。
token是大模型自己学会的一套文本切分规则,他并不等同于汉语词汇的概念。对英文来说虽然大部分是一个单词(例如hello是一个token)但也不绝对是这样的。
openai有一个在线工具可以做测试: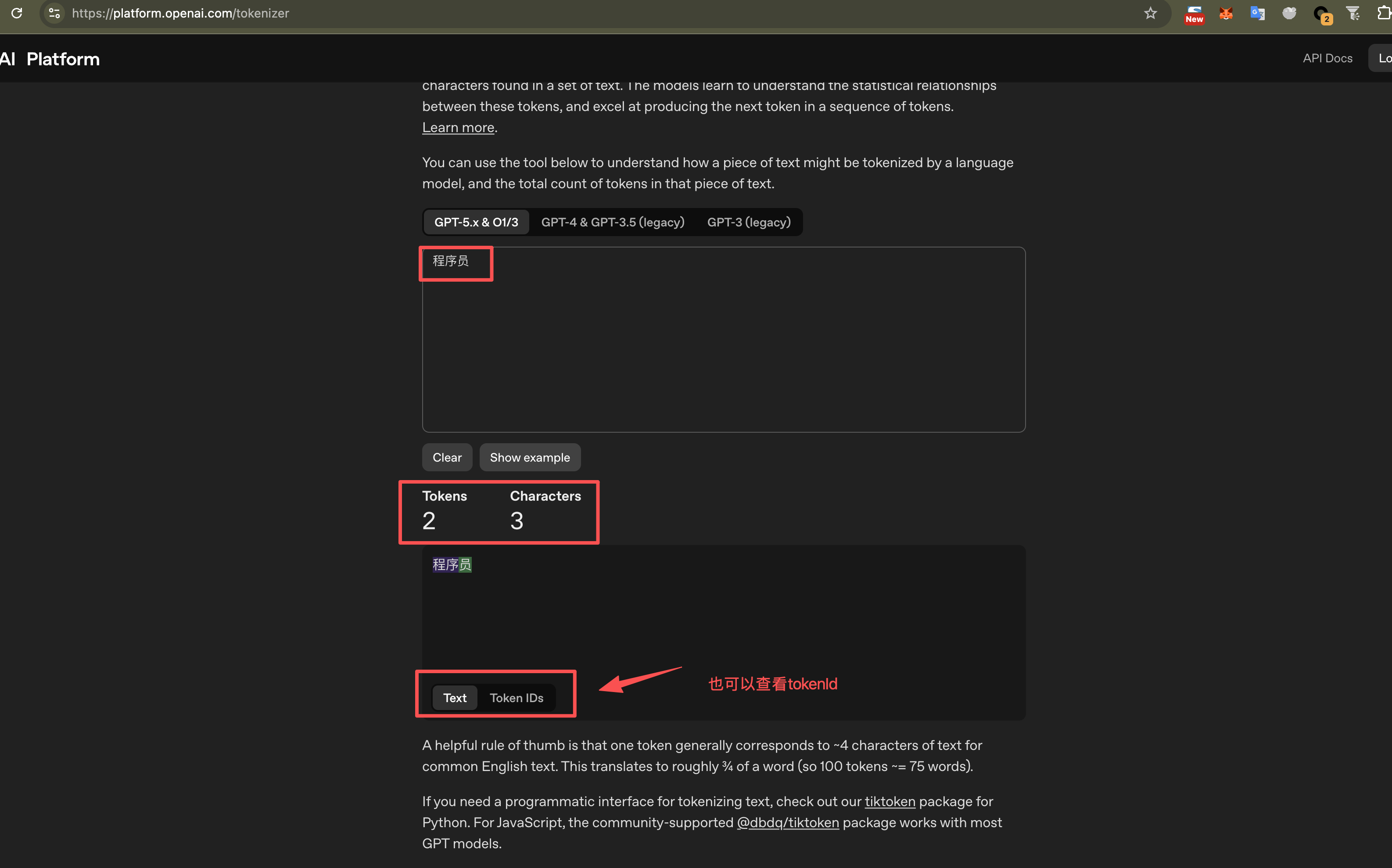
平均来看1个token大约等于0.75个英文个单词和1.5-2个汉字。所以,咱们平常汉字是得按字来记忆,英文咱按单词来估算。由于这玩意影响咱们的付费,所以后续咱们可以这么记忆:
n万个token,大概等于1.5n到2n个汉字。大概等于0.75n(即四分之三n)的英文单词。
context上下文
是指的跟大模型交互过程中的“输入内容-对话历史”、“输入内容-用户问题”、“输入内容-工具列表”、“输入内容-systemPrompt”、“当前输出”。这些都是上下文。
上下文窗口
即context所能容纳的最大token数量。
主流模型能容纳的token数大概在100万左右。例如GPT5.4,Gemini3.1Pro,ClaudeOpus4.6都是100万token。
100万什么概念?我们用上文的token公式大概知道是150万多的汉字,75万左右英文单词。150万汉字什么概念,大概是一本哈利波特吧。
prompt
prompt提示词分为系统提示词(system prompt)和用户提示词(user prompt).
- 用户提示词:用于说明执行的具体任务。
- 系统提示词:在后台配置好,用于说明他的人设和和做事的规则。
举例:
疑问:
- 系统提示词配置我要去哪里配置?
- 他跟我直接把两段提示词直接合并成一段文字提问给大模型有啥区别?
回答:
- 通常来说对客的系统中他们可能会提供让你设定角色的功能。如果咱们是编程的话,他们的api会暴露一个systemPrompt字段。或者说必须让你给他传递的messages里面有一条叫做:[{role: ‘system-prompt’, congent: ‘xxx’}]这样的系统提示角色的消息在里面。
- 虽然两段话合起来直接以用户提问的形式交给大模型也原理差不多。但是ai大模型其实内部有微调,他确实接收到[{role: ‘system-prompt’, congent: ‘xxx’}]这种系统提示词后他对系统提示词的权重会设置为最高,这样可以放置用户的语句里的规则覆盖掉系统提示词的规则导致出问题;另外系统提示词他们可以进行适当缓存,这样其实你每次提问的时候尽管传递了系统提示词但其实并不会消耗你额外token; 另外你如果把系统角色提示放到用户提问了提交,会让大模型误会成要总结一下你的提问之类的,总之他可能听不懂是要设定自己的角色。
tool工具
工具不能直接被大模型调用。因为LLM仅仅具有的能力就是接受文本输入再回复一段文本。
于是tool要想被用起来,就得有个“平台”概念存在。他是用于串起来整个流程。
平台在把用户提问告知大模型的同时,他还会告知平台上有哪些“tool工具”。(好吧,你有没有发现,完成一次模型提问,现在已经有一堆东西要传给模型了,例如“系统提示词、历史上下文、可用的tool工具、用户的本次提问内容”)
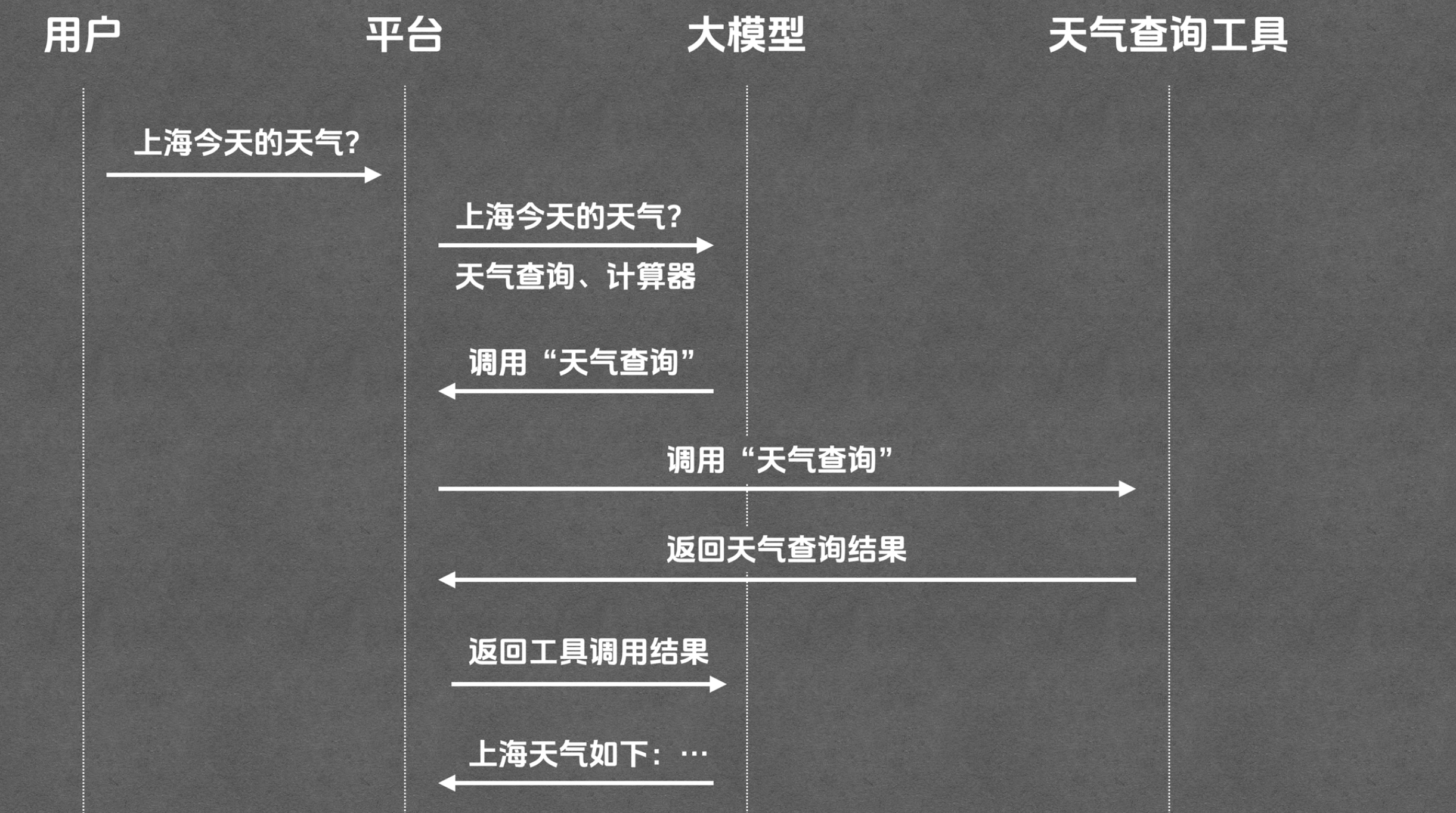
其中调用环节大模型会组织好调用参数给到平台,平台来完成调用哈:

MCP
tool规范化就成了mcp。tool比作是函数的话,一个mcp就是多个函数的集合的一个服务。
mcp装到本地的描述文件,大概他要包含name和description,同时还定义了入参的jsonSchema。因此他有个比较大的缺点是,他每次要把平台的所有mcp工具都发给大模型的话,一旦你装的mcp多了,那么发给大模型66个mcp可能要花费1万token,sonet模型大概要3毛钱哦。

CLI
cli模式,在发给大模型的时候,就不用把mcp发给大模型了。于是我们只需要给大模型发一个bash命令就行了。
bash的描述也很短。

这样大模型就只需要收个bash信息,就可以了。大模型学习了大量可以用的一些cli命令(例如图片处理工具、git工具等),所以大模型可以直接给你返回要用的cli命令。
至于一些自定义的命令,就像skill一样给他准备一份说明文档就好了。
但我感觉:其实mcp只是没做“渐进式披露”吧。如果mcp也只暴露name和descrption,等真正用到的时候再去读jsonSchema入参出参描述,那不就跟skill带来的token消耗量是一样的了吗。(只不过即使传递name也会比cli花费token而已)
cli工具也有缺点:
- 有可能出错,甚至有危险命令生成就很危险。
- 不如mcp稳定。容易出错。因为没有结构化输入,都靠模型经验。
vibe coding
概念
工具
vscode+内置的cody。
他具有哪些能力呢。
cursor
claudcode
RAG
rag是向量数据库。他通常用来解决大模型回答问题时候的“参考资料”问题。
设想我们有个产品手册,我们不可能每次用户来给我们AI客服提问的时候,我们都把“用户问题+一本产品手册”交给AI大模型,毕竟大模型他的上下文是有限的。于是我们可以先基于用户问题去产品手册里找到跟这个问题最相关的部分内容,然后把这部分“命中的相似内容”再加“用户问题”一起发给大模型,这样大模型回答的时候就能把产品手册的内容回复出来了,且没有撑爆大模型上下文。
即:
- 为了避免撑爆上下文,我们不得不采用rag。
- 成本。即便你的文档从 100 万字增长到 1 亿字,RAG 的检索效率和单次调用的 Token 消耗几乎保持不变。
- 性能。计算成本与延迟:每提一个问题,都把 150 万字重新“读一遍”,会导致极高的 API 调用费用,且每次回复的延迟(Latency)会因为模型要处理海量无关信息而变得极长
- 大模型分析context的准确度。“迷失在中间”现象 (Lost in the Middle):研究表明,当上下文极长时,模型对输入内容中部的注意力会显著下降,导致检索准确度降低。
- 这是 RAG 最大的商业价值。由于是基于检索到的文本生成的,你可以清楚地告诉用户:“这条结论来自我 2026 年 3 月写的关于 React Fiber 的博客”。这使得 AI 的回答变得“可审计”和“可信”。
rag的基本流程: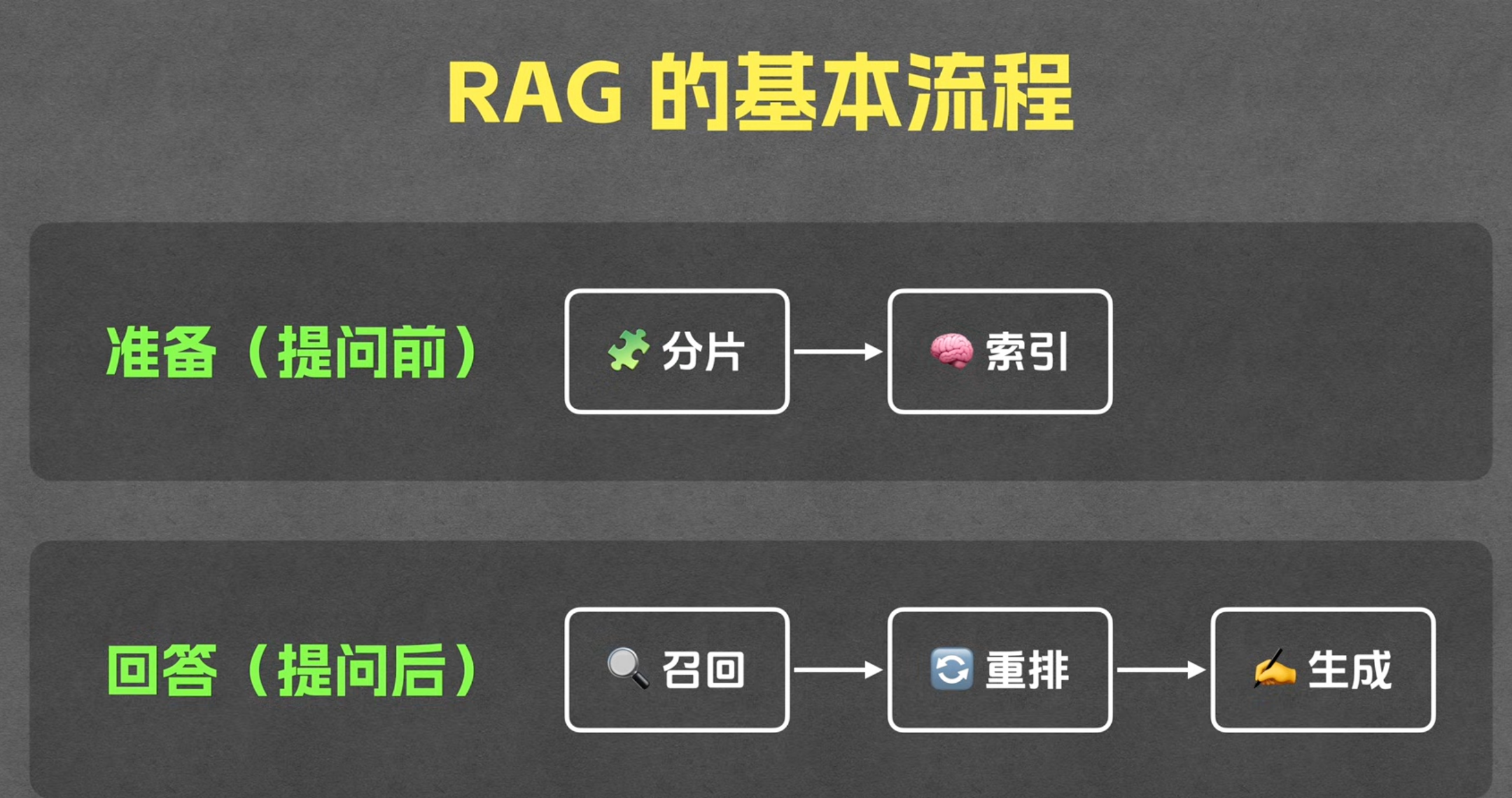
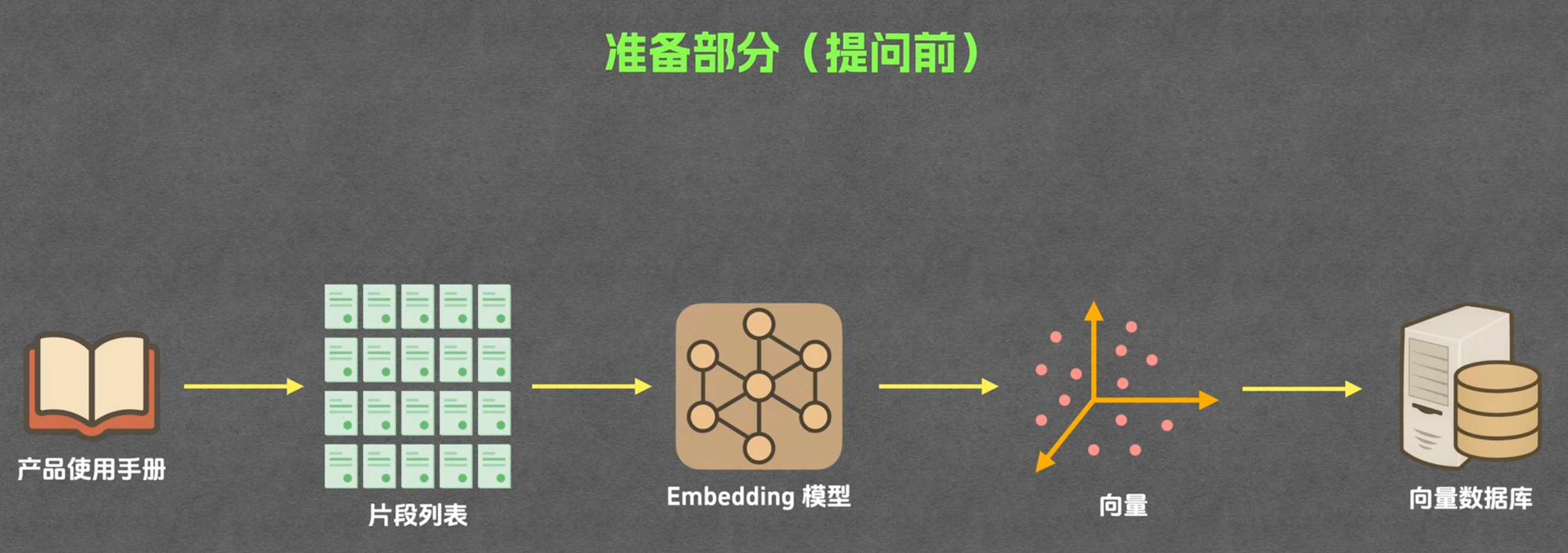
存储阶段
分片
分片就是先把你的文章信息给你分成一个一个的小片段。可以是几个单词一个片段,也可以是一个段落一个片段,也可以是一个句子一个片段。
索引
索引是指的的完成上述分片后,把他们各个分片存入数据库的过程。他分为2个步骤:
embedding向量化
分片后他就要把片段和片段对应的向量存到RAG向量数据库里面去。
这里就涉及到要把你上一步分的片给他转成向量。这个是通过embedding模型给转的,embedding是一种大模型向量化技术(他也是一种大模型,但他干的是向量化的技术—即语言转数字向量的事情)。
要理解embedding转成了啥,我们得先理解向量:
向量在数学上是有方向的量。例如一维的[1] [3] [-4]; 二维的 [0, 1] [1, 7] [2, 4] 。 当然还有三维甚至更多维。在AI场景下这个向量通常是大于3维的多维,这玩意可能有点难以想象成几何画面。
然后,我们的文字分片假设转换成了绿色、黄色、蓝色箭头的那3个向量,如图所示: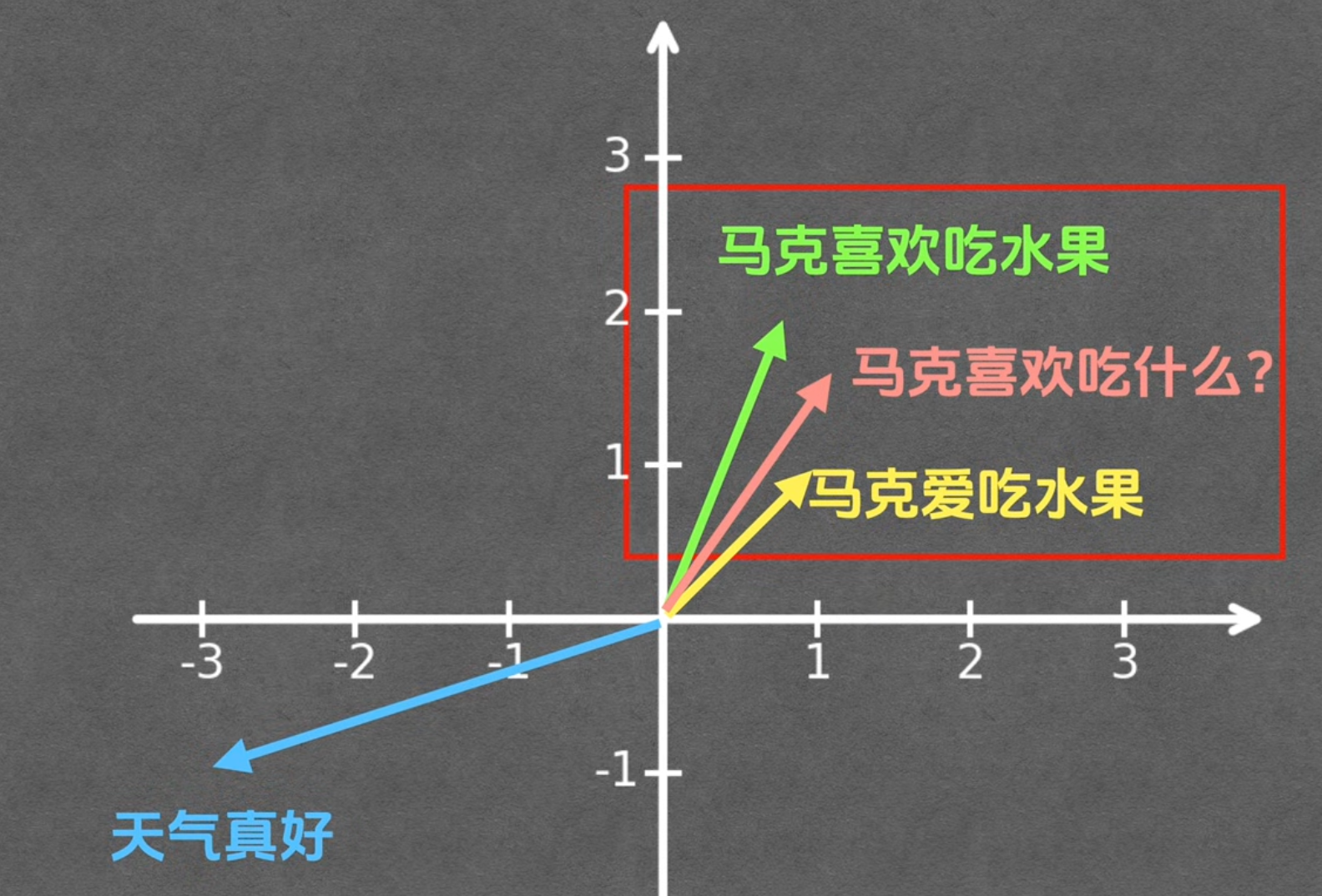
那么,当有个人提问了一句“马克喜欢吃什么”,然后我们会把“马克喜欢吃什么”转成向量,然后丢给RAG数据库去找根这个问题向量最接近的向量,于是就找到了粉红色箭头旁边的“马克喜欢吃水果/马克爱吃水果”。
要完成embedding向量化这个动作,可以参考这个embedding大模型排行榜:https://huggingface.co/spaces/mteb/leaderboard。可以看到中国的千问还是排名比较靠前的。
存入数据库
向量化之后就要把向量存入RAG向量数据库,然后向量数据库中他不止要存储转换后的向量,通常他还要存储原文。这样我们查出相似度的向量后就能自动把原文拿到了(毕竟我们实际场景下是为了查出想要的原文内容哦)。


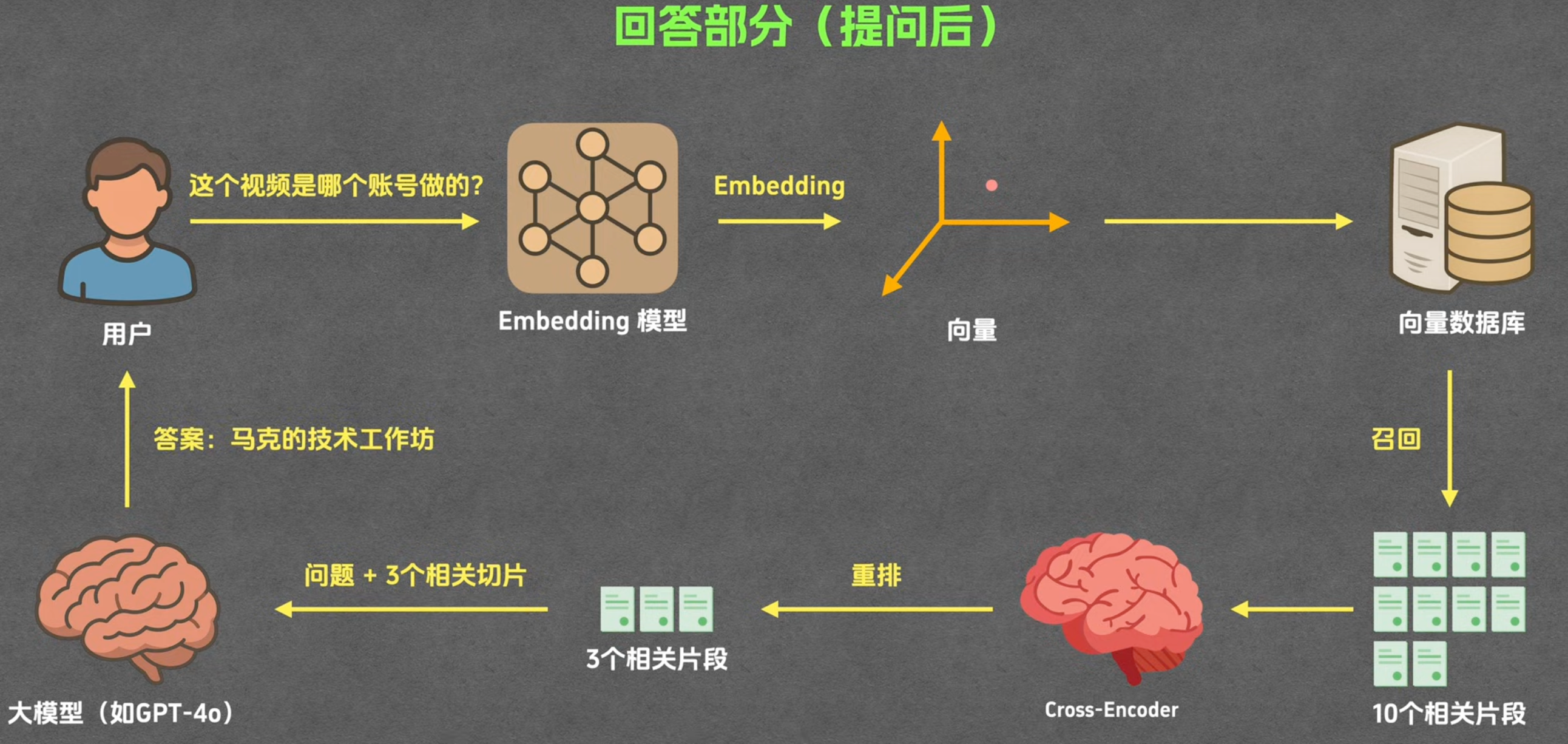
回答问题阶段
当进入提问阶段,则要经历召回—重排—生成3个步骤。
召回
大概流程是这样的: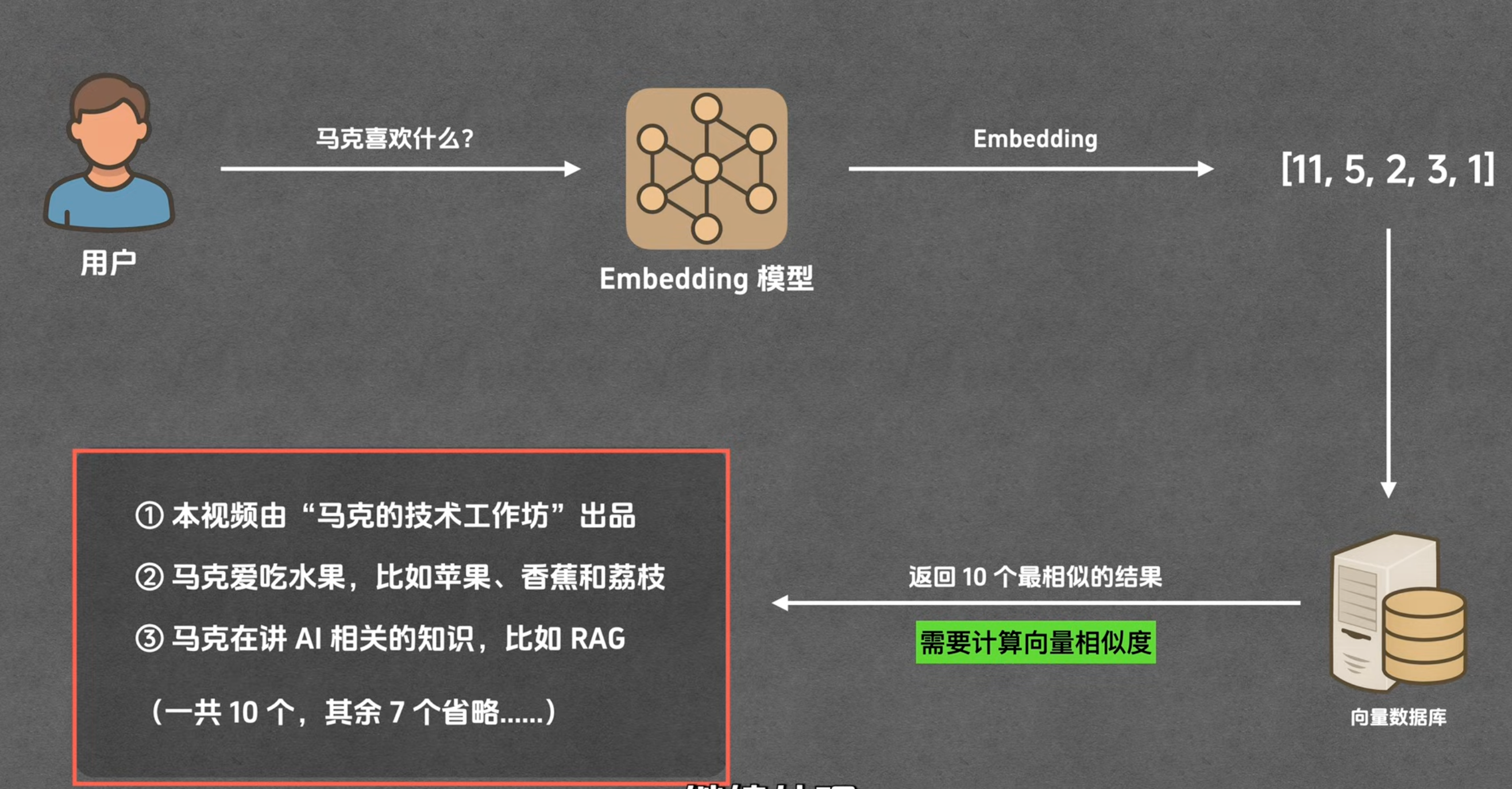
向量数据库在进行相似度检测时,大概是这样的步骤:
- 先embedding把问题转成向量
- 对RAG数据库中每个向量都运行该函数:isSimilar(问题向量,RAG中已有向量)得到相似度值。 (这里的函数算法通常是求两个向量的“余弦”,或者求“末端点距离”,或者求”B到A的垂线乘以A长度“)
- 之后返回上述相似度值最高的10条向量和原文。
重排
即从上述10个结果中再次挑出最符合用户问题的3个结果。
为何不在召回阶段直接取3个?因为重排算法不一样,通常效果会更好。
重排通常采用cross-encoder的模型算法,因为他相比召回阶段的速度优势而言,cross-encoder具有准确度高的优势,适合精挑细选。
生成
生成用户的回答就比较简单了。当下我们有了上面“重排”拿到的精挑细选后的rag结果,然后我们再把他跟用户问题拼起来,一起交给LLM大模型,就可以让大模型来生成最终的回答了。
复习RAG整体流程
Agent
什么是agent。其实上面我们讲了LLM配合tool的时候,那里需要有个平台来把流程串起来。当平台拥有足够多的tool来完成复杂的任务的时候(例如多次调用多个tool完成一个任务),那么看起来这个平台就具有自主规划和调用工具能力。此时就叫他agent。
举例子: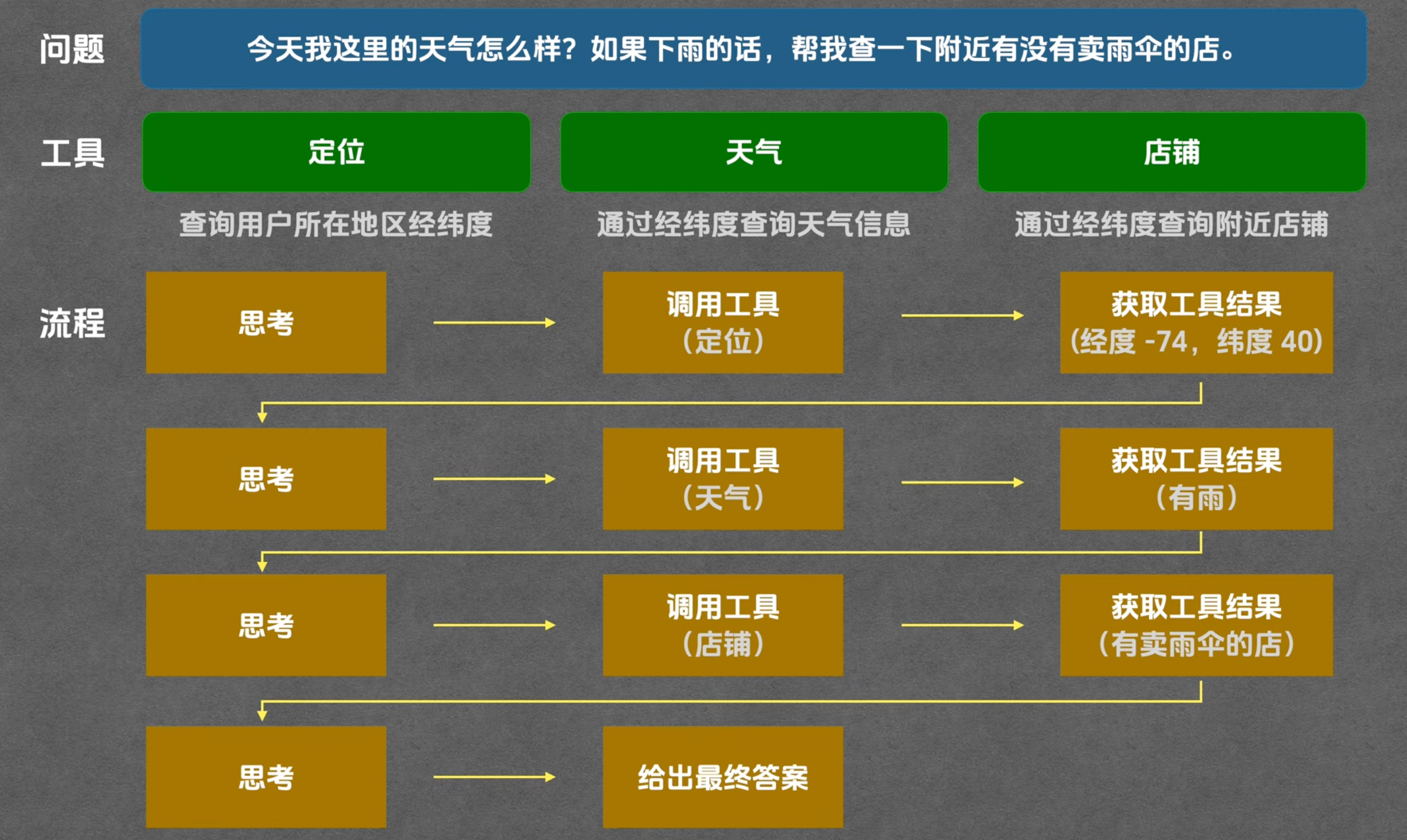
agent智能体架构
ReAct:
计划+执行框架。
多Agent(Multi-Agent)系统:
skill
如果你希望做一个agent助手,然后你问他问题的时候,能让他按照你设定的一些规则来回答(包括输出格式,包括思考答案的规则),那么你不可能每次问他问题都把规则告诉他。
例如: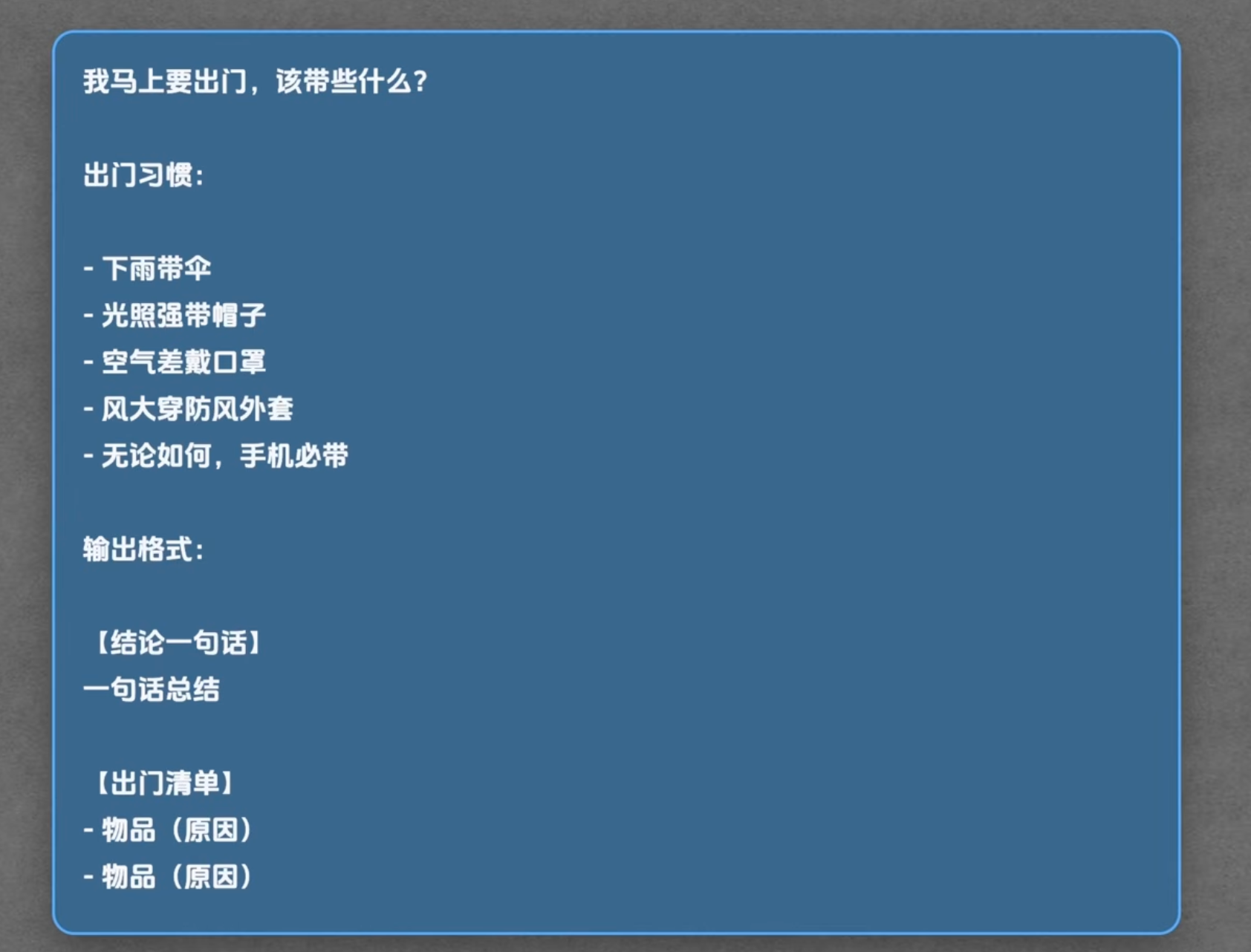
于是你想到,是不是可以用系统提示词让这个助手自动知道自己角色和规则。
我感觉是可以的,但是我在youtube视频里看到老师说用skill来解决这个问题。于是我便思考这个场景下到底改用系统提示词还是用skill。
最终我的思考是这样的:
Prompt 是“管家的性格与守则”:
它决定了管家是对你毕恭毕敬还是幽默风趣,决定了管家在处理紧急任务时是否必须向你汇报。它定义了工作流程的“规则”。Skill 是“管家的工具箱”:
里面装着计算器、扫地机器人、电话等。管家(模型)根据你的要求(Prompt),判断现在该用什么工具(Skill),调用后将工具反馈回来的客观结果,翻译成自然语言告诉你。例如当前这个例子,对于管家来说,他能给我提供“出门穿戴建议”只是他作为管家的智能之一。因此既然是职能之一,我不可能把所有职能都写到一个agent的系统提示词里,我可能还是要写成一个skill给这个管家安装上。这样管家就可以无限扩展他的技能了。
出门清单skill实现举例: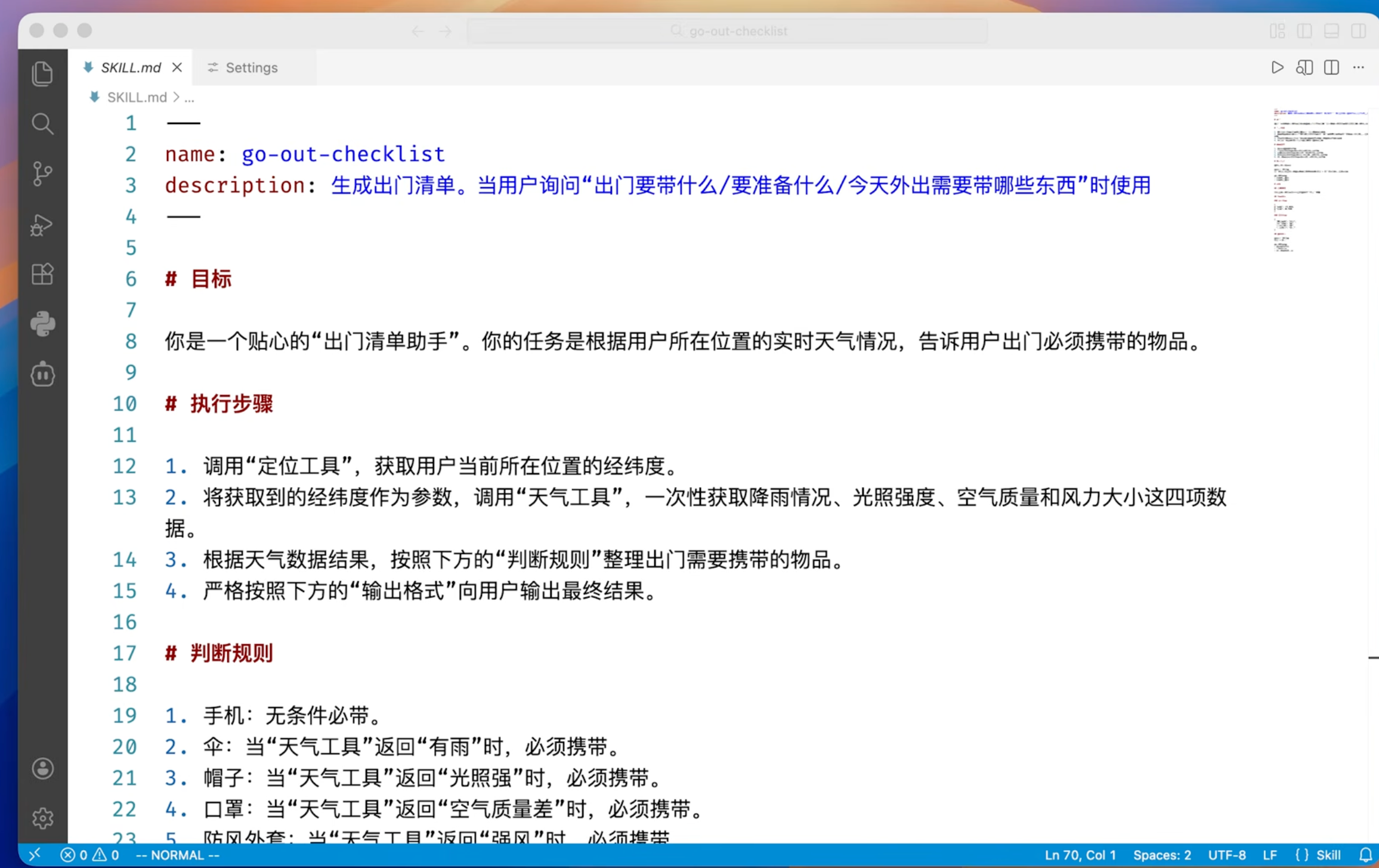
把他命名为go-out-checklist/SKILL.md,然后把这文件夹放到 ~/claude/skills目录下就等于给claudeCode安装上了。安装后默认claude只是会读取skill的元数据层(即名称和描述),并不会真正运行他的指令层内容。
打开claudeCode输入/mcp可以看到本地已经安装了的mcp,他们是这个skill能用的必备条件哈: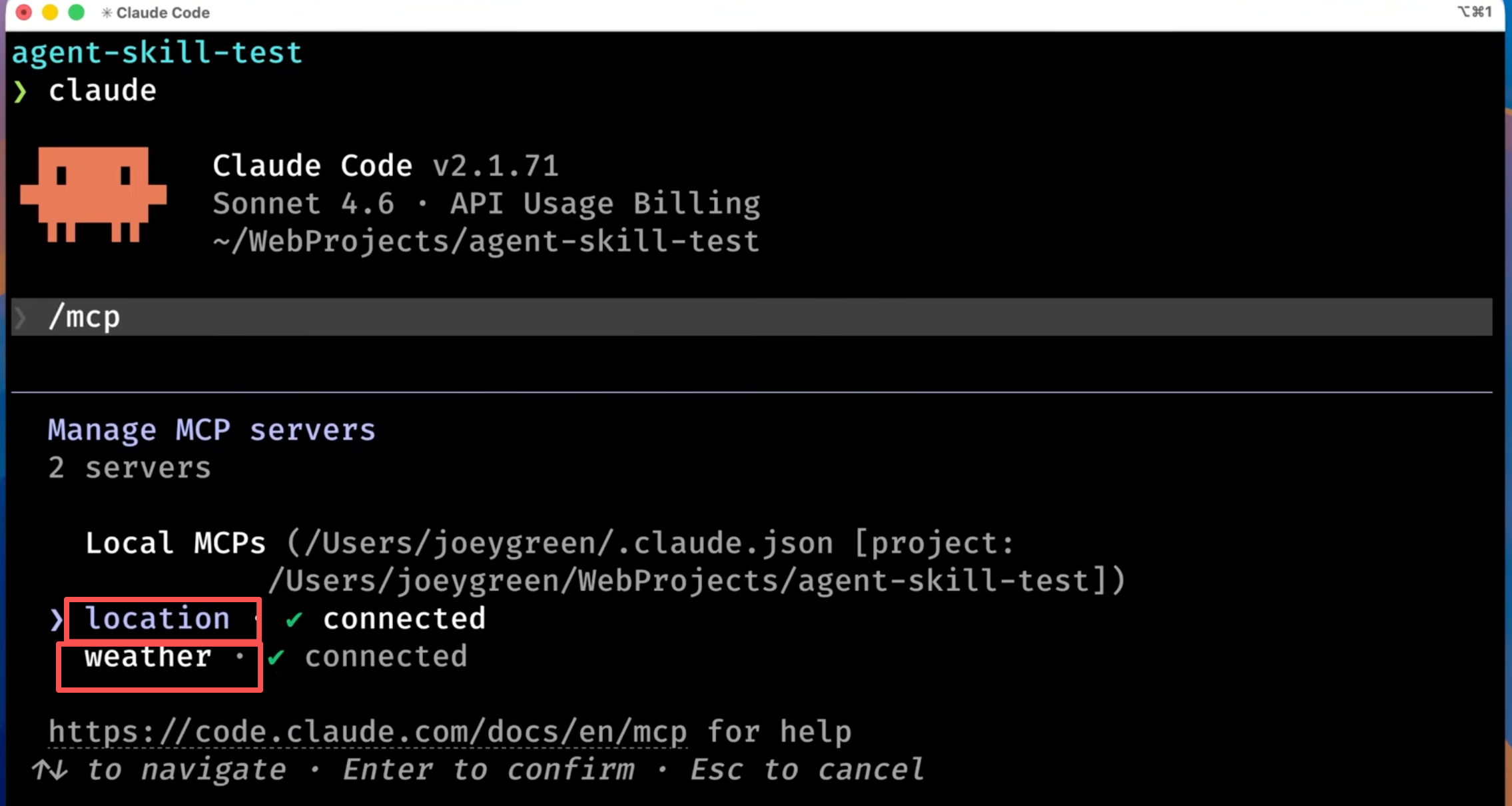
个人ai分身设想
打算做一个 ai.cuiyongjian.com的站点,打开后就是一个chat类型的ai分身对话框。
- 对于任何访客来说他都可以提问,他可以读取我设定的所有非敏感数据进行回复。
- 如果是登录态(即我本人),则我可以以主人的身份去询问他,他以我的分身向主人汇报的口吻来回答。此时可以读取一些主人敏感数据。
openRouter
可以聚合各个模型的apikey。
模型选择
品牌区别
- chatgpt。聊天做科学很专业。非常注重安全和政治正确。
- codex:openai做的用于写代码的,但是文案能力不太行。推理能力比较强。毕竟是github数据训练出来的。通常可以用claude写代码,然后codex来review代码。
- claude。写文案写的好。
- gemini。在一些小众领域提供一些意见他都可以提供。他比较顺从用户。想法多,是个比较激进的模型,但不太愿意回答比较严谨的内容。他可以调用谷歌的搜索,这是优势。他“画图、作曲”很强。
参数量类型区别
模型有不同参数类型,8b参数,128b参数,他们正式名称叫 参数量 (Parameter Count)。B (Billion): 代表“十亿”。8B 就是 80 亿个参数。
参数就是模型里的权重(Weights),你可以把它理解为模型大脑里神经元连接的“粗细”。这些数字是固定不变的,存储在硬盘里的模型文件大小(几个 GB)主要就是由这些参数决定的。模型加载到显卡里,这 8B 个参数必须先找个地方坐下。计算公式:
如果你用的是 FP16(16 位浮点数),每个参数占 2 字节。8B 模型就要占 16GB。如果你用的是 4-bit 量化(像 Ollama 默认那样),每个参数只占约 0.5 字节。8B 模型只需要约 4.5GB。特点: 只要你不换模型,这块显存是死雷打不动的,跟你聊不聊天没关系。
在 8B 模型上,开启 32k 上下文可能会额外吃掉 2-4GB 显存;如果你强行开到 128k,光这个缓存就可能把 24GB 显存的显卡撑爆,哪怕模型本身才 5GB。
上下文长度区别
模型上下文长度。这个是模型自身的极限。模型的“上下文长度”(能力上限),当你看到 DeepSeek 说支持 64k,或者 Claude 说支持 200k 时,这指代的是模型的 “物理极限” 或 “设计容量”。这是模型在训练阶段就定死的能力边界。就像人的“短时记忆容量”,模型大脑的设计结构决定了它处理超过这个长度的信息时,注意力机制(Attention)会崩坏,逻辑会完全乱掉。理解为一个桶的最大容积。不管你给它换多大的显卡,这个桶本身就只能装这么多水。
哪怕你把 max_tokens 设成 10000 也没用,因为物理上限已经到了。
这就是为什么在处理大型 Monorepo 项目时,我们不仅要看模型强不强,还要看它的上下文上限够不够大。如果上限不够,它就没法“通读全文”后再给你写代码
模型的api调用
api接口调用方式
入参学习
通常来说,有几个重要入参或概念我们要学习下:
ctx_num,这个通常在调用ollama本地模型的时候才有。他表示上下文大小限制。即使你装了一个8b模型然后又128k上下文的情况下,你的显卡通常来说你也只能给他设置一个num_ctx为8k。
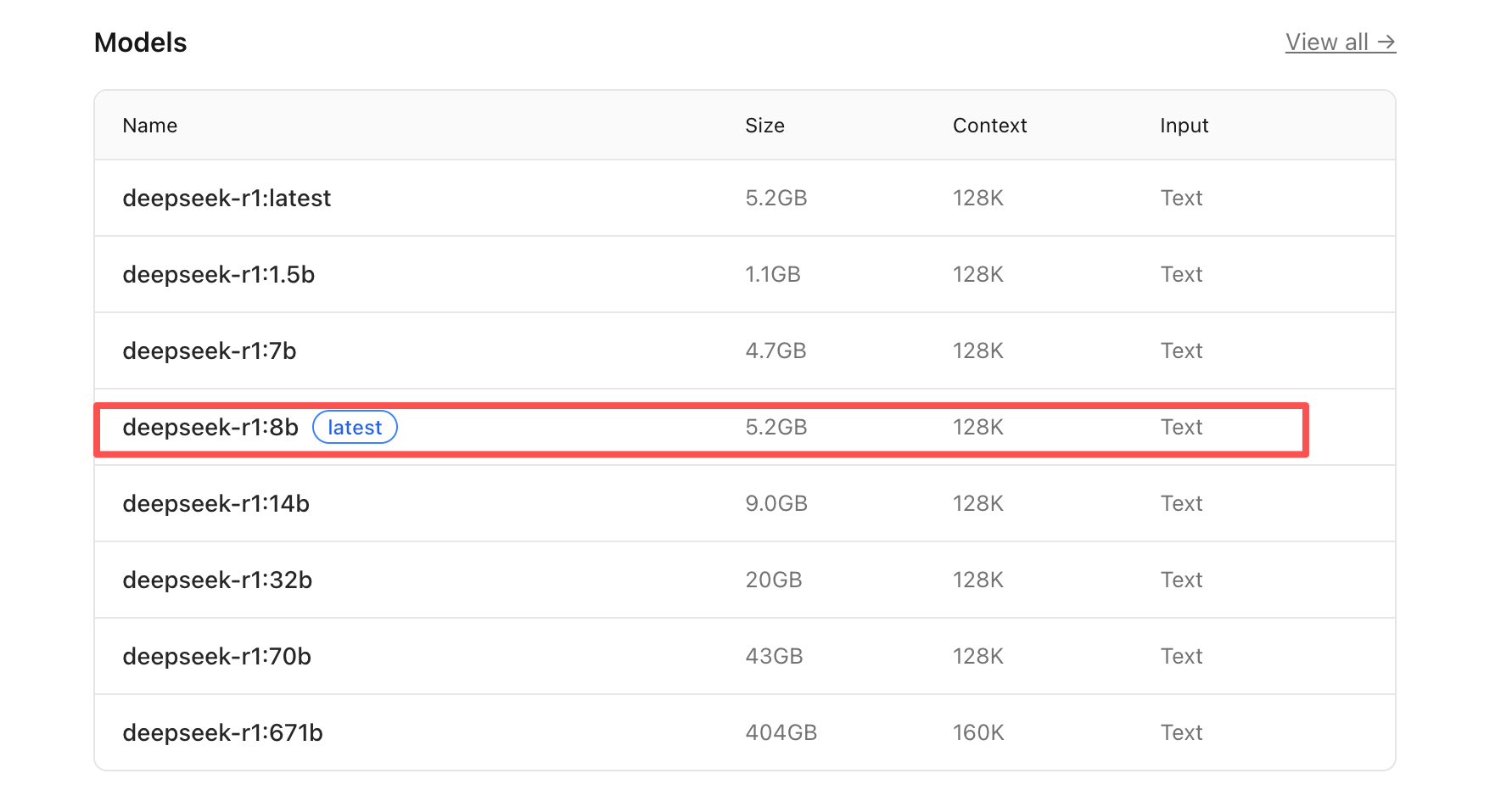
因为,首先8b的模型参数他放到你显卡里就占用显存大概4G多,然后剩下4G给你用。然后模型在回答问题生成回答token的时候,他是通过kvCache来实时回看你的输入内容,这一一系列操作对于”输入+输出合计8K上下文的情况下“就会占掉将近4G的显存,于是你num_ctx得设置8k。
也就意味着:尽管deepseek8b这个模型上下文(输入+输出)有128k,但在你的显卡上跑的时候你也只能给他搞个8k上下文。
当然云端api调用的时候你就当做128k就好了,因为官方api写多少他肯定就用多大的显卡去跑了。max_tokens: (num_predict 是 Ollama 版的 max_tokens)。这个表示的是输出token大小。他能起到一个作用就是能让模型感知到他回答问题时候输出的上限大小。
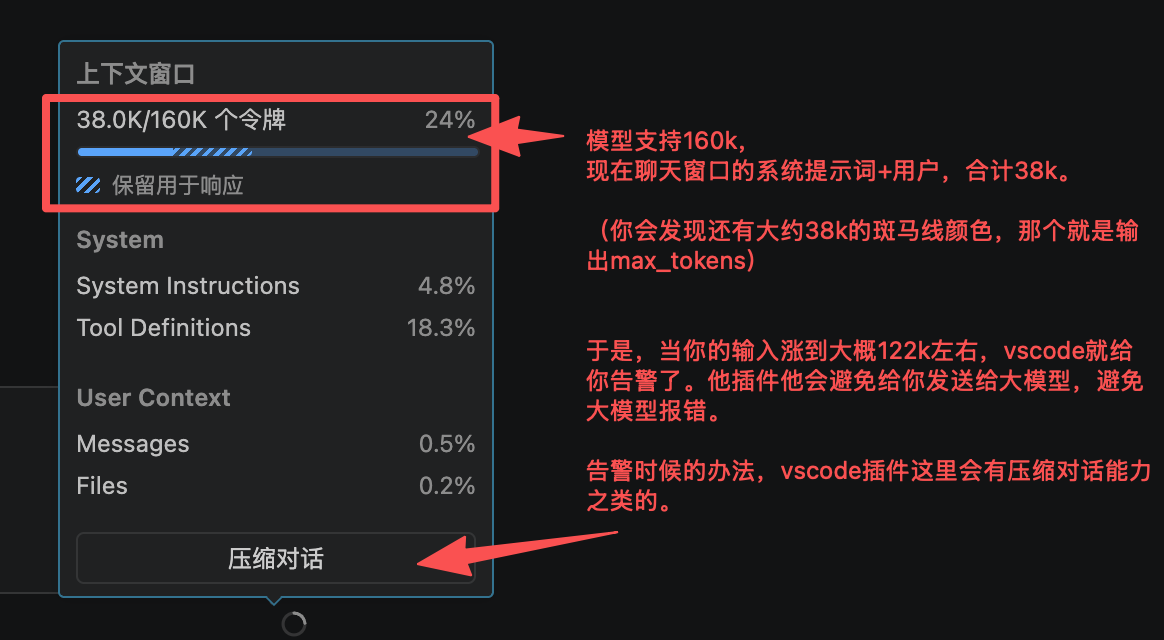
于是这里就出现一个问题:模型总上下文是128k,然后你还可以靠max_tokens配置输出的最大大小。那么一旦提问的时候问多了咋办。- ollama的表现:他是截断你的输入,保证输出。可能会影响模型对你提问的理解。
- 云端api表现:你直接调用模型官方api的话,由于官方api他知道你想要的max_tokens,且他知道你提问的大小,于是他会给你报错contextLimit,直接不干了。
- vscode等插件。他在提问给云端模型之前,他就会先提示你压缩上下文,或者删除一些at的文件之类的。
stream: true或false。